testomat.io управление авто тестами
testomat.io управление авто тестамиЗдравствуйте!
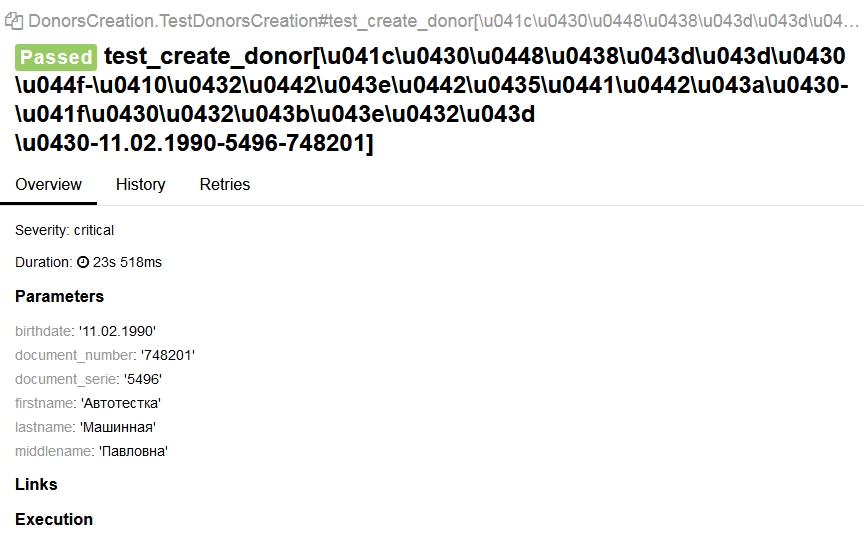
Есть тест, написанный на pytest. Для передачи тестовых данных функции я использую @parametrize, передаю туда функцию, которая читает данные построчно из csv-файла (get_data(название_файла)), в котором есть строки на кириллице. Проблема заключается в том, что в Allure я получаю вместо кириллицы символы на юникоде. Само название шага теста @allure.step('Кириллицей') отображается корректно, но здесь:
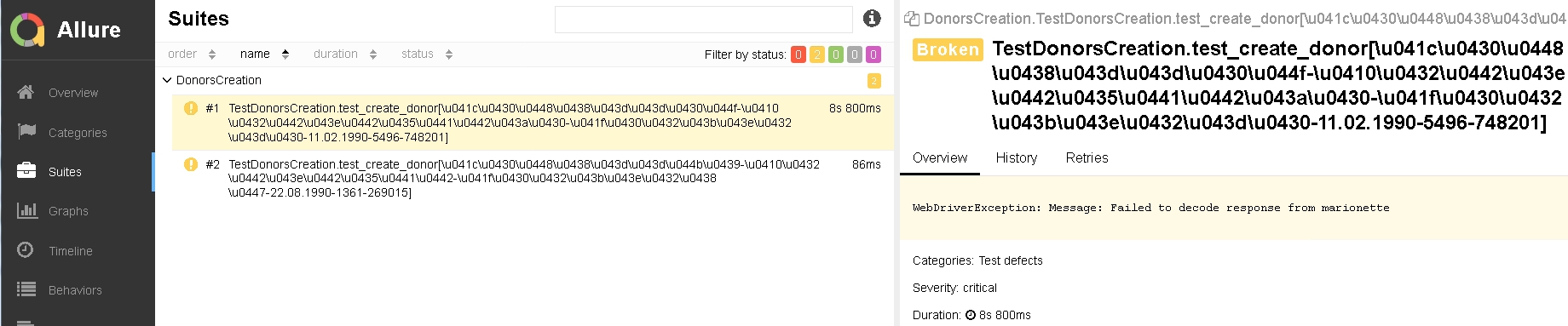
в месте, где должны отображаться конкретные тестовые данные, получаю то, что вы видите на скрине.
Я пробовал сохранять свой csv-файл в кодировке “Windows 1251” - тщетно (в интерпретаторе, например, символы после вызова функции get_data(file.csv) отображались корректно, а в самом файле после сохранения имели вид “Ìàøèííàÿ,Àâòîòåñòêà” Пробовал сохранять в кодировке “utf-8” - тоже (здесь же в файле отображалось всё хорошо, но в интерпретаторе на выходе получались похожие символы). После сохранения в “utf-8” я добавил в функцию get_data такой метод, как fix_encoding (отсюда: python-ftfy/ftfy at main · rspeer/python-ftfy · GitHub), после этого из файла в кодировке UTF-8 на выходе получалась понятная строка на кириллице, но в отчёте на Allure ничего не изменилось.
Pytest v.3.2.3, Pytest-Allure-Adaptor v.1.7.8, python 3.6.3
Подскажите, пожалуйста, с какой стороны к этому подойти? Это проблемы в кодировке Python? Или же какой-то баг в Allure?
P.S.: во всех случаях в браузер, когда выполнялся тест, передавались корректные символы на кириллице (и с сохранением в 1251, и в UTF-8), проблема только в Allure.
Заранее спасибо!