 testomat.io управление авто тестами
testomat.io управление авто тестамиВсем привет! Хочу сделать небольшой гайд по xpath в контексте тестирования web-приложений с целью систематизировать свои знания и помочь начинающим.
Гайд состоит из 2 частей:
- Немного теории про то, как, собственно писать xpath;
- Проверка и отладка написанных xpath в консоли браузера.
Поехали!
1. Теория
Для начала нужно понять, с чем мы работаем. Для этого возьмём страницу https://www.google.com/ (ничего нового) и нажмём F12 на клавиатуре:
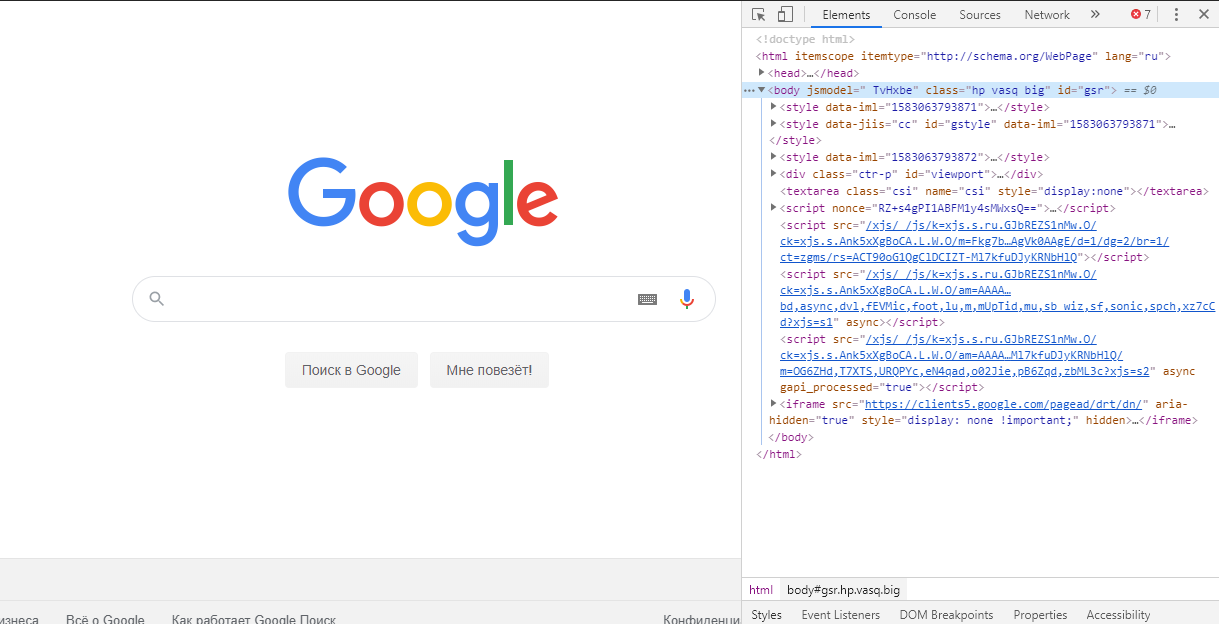
Слева у нас сжавшаяся страница гугла (таким образом, кстати, можно проверять поведение страницы при изменении расширения, просто уменьшая-увеличивая область страницы), справа панель разработчика со стандартно открытой вкладкой Elements. На этой вкладке у нас DOM-модель страницы, в которой и находятся элементы страницы.
Попробуем найти кнопку Картинки справа вверху страницы. Для этого нажмём на неё правой кнопкой мыши и затем Просмотреть код
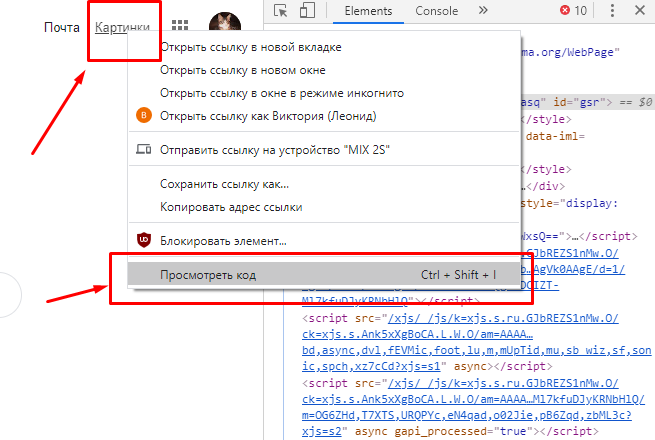
И увидим этот элемент в дереве:
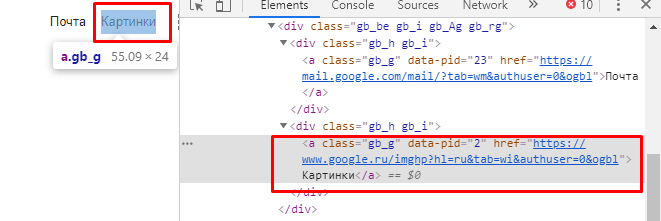
Как нам теперь найти эту кнопку по xpath? Посмотрим, что тэг элемента “a”, атрибут class = "gb_g", а вложенный текст “Картинки”.
Для зануд
Да, можно писать css-селекторы, но сейчас речь об xpath;
Да, искать по тексту не самая лучшая затея, если мы будем использовать разные языки.
Задача - показать, как составлять как можно менее хрупкие локаторы
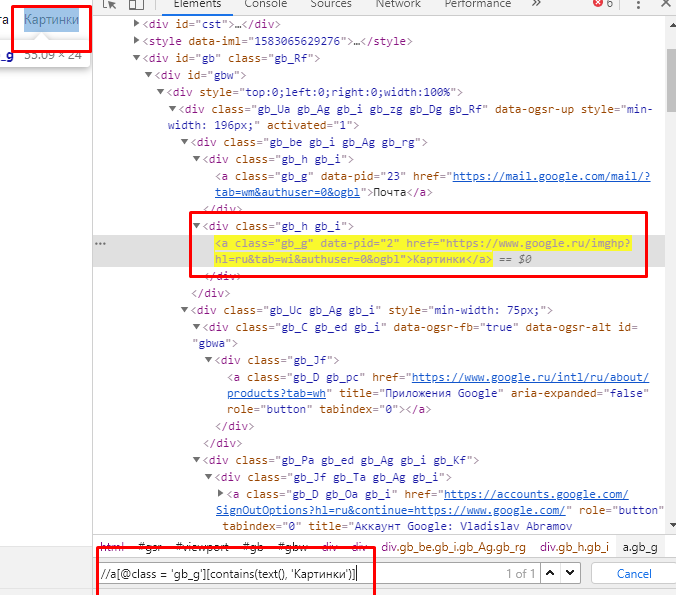
Давайте напишем этот xpath:
//a[@class = 'gb_g'][contains(text(), 'Картинки')]
-
//- для указания поиска от самого начала -
a- тэг элемента -
@class- через @ передаем название атрибута, а в одинарных кавычках его значение -
contains- указываем, что будем искать, не передавая полное содержимое атрибута или свойства, а часть искомого значения; через запятую в круглых скобках в чём должно содержаться и что именно -
text()- так как текст - это не атрибут (подскажите в комментах, что это такое, пожалуйста), то его передаем со скобками без @ -
'Картинки'- что именно ищем в text().
Теперь давайте перепишем этот xpath:
//*[local-name() = 'a' and contains(@class, 'gb_g') and text() = 'Картинки']

Что поменялось?
- мы использовали один набор квадратных скобок, в которых условия поиска передали через
AND, то есть искомый элемент должен соответствовать всем переданным условиям -
//- поиск от самого начала -
*- элементы с любыми тэгами -
local-name() = 'a'- отсев по тэгу. Используется, если у вас кастомные тэги во фрейворке фронтенда, по которым selenium не может найти элемент как в первом примере. Тогда просто говорим в xpath, что сначала ищи со всеми тэгами, а потом отсеиваем по свойствуlocal-name() -
contains(@class, 'gb_g')- поиск элемента, в атрибуте @class которого будет'gb_g'Аналогично поиску по тексту в первом примере - указали, что искать будем в атрибуте class подстроку gb_g -
text() = 'Картинки'- свойствоtext()должно быть именно равноКартинки, а не содержать в себе такой текст.
В принципе, этого уже вполне достаточно, чтобы находить элементы с заданной точностью. Теперь надо поговорить о том, зачем используются xpath-локаторами.
Оси xpath
Осями называют функции перемещения по дереву в любом направлении. Например:
- Найти всех предков текущего элемента -
ancestor:: - Найти всех потомков текущего элемента -
descendant:: - и куча других, почитать тут Оси языка Xpath — Umicms
Для чего это используется?
Если у вас на странице много однотипных элементов, к которым нельзя написать уникальный локатор напрямую (чекбоксы, радиобаттоны и тому подобные штуки), но рядом есть другие элементы с уникальным текстом или другими атрибутами и свойствами, за которые вы сможете зацепиться.
Допустим, нам надо получить количество ответов в какой-то теме на этом форуме:
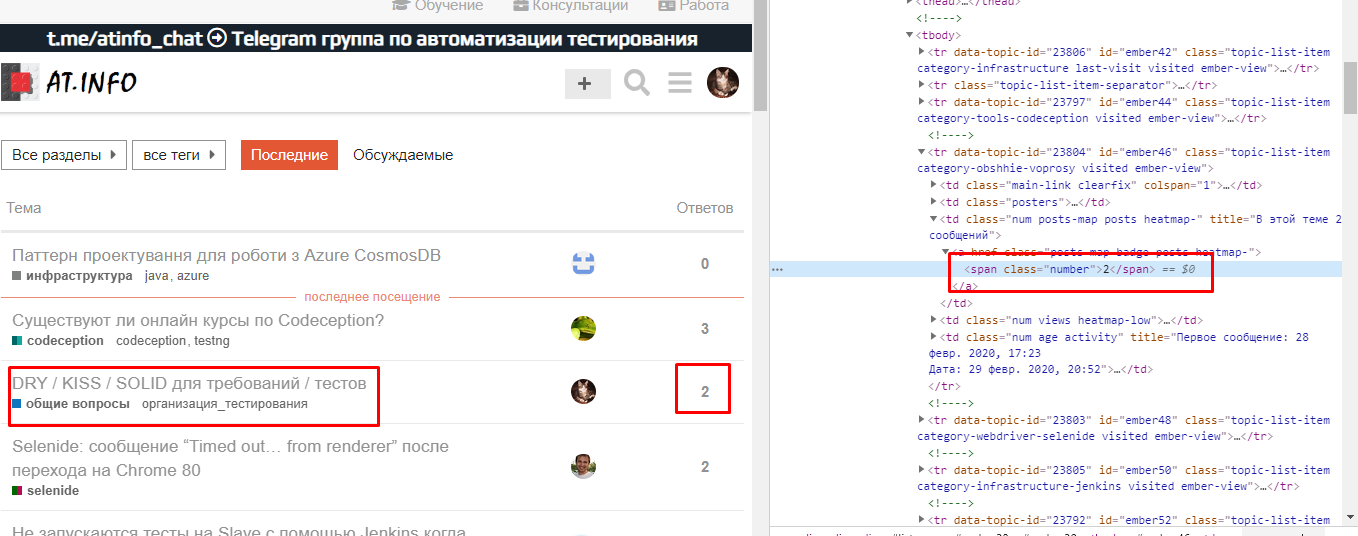
Думаю, очевидно, нужно каким-то образом завязаться на название темы, чтобы затем как-то через неё получить количество ответов. Посмотрим на DOM-модель:

- Найдем элемент, содержащий название темы
- Поднимемся до элемента строки, в которой находятся вся информация по конкретной теме
- Спустимся до элемента с количеством ответов
//*[contains(text(), 'DRY / KISS')]
/ ancestor::*[contains(@class, 'topic-list-item')]
/ descendant::*[contains(@class, 'posts')]
/ descendant::*[@class = 'number']
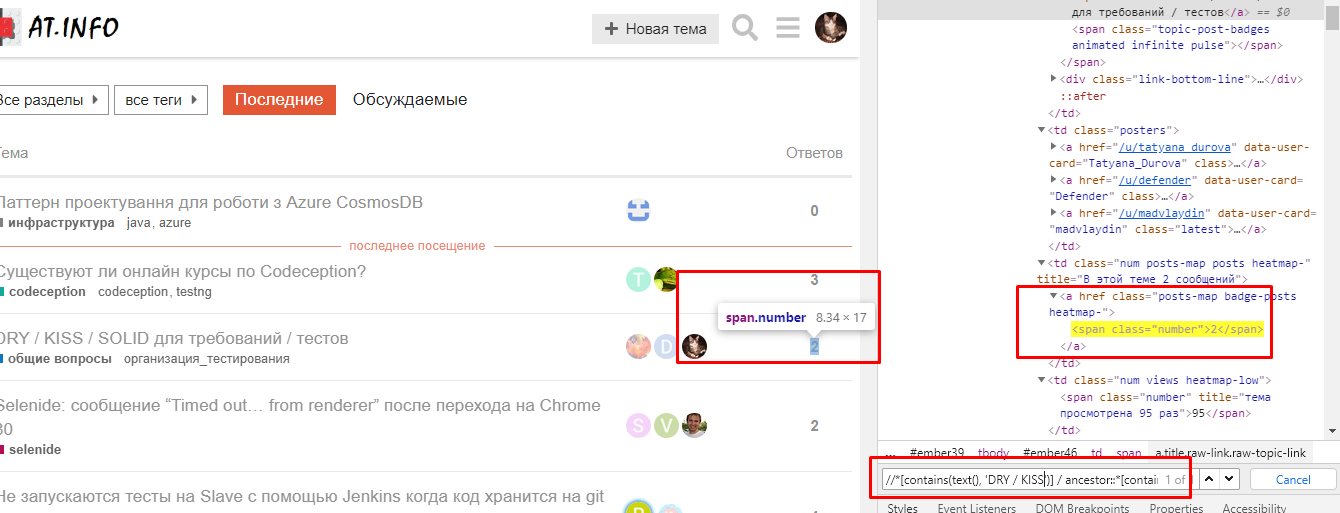
-
//*[contains(text(), 'DRY / KISS')]- нашли элемент с названием темы -
/ ancestor::*[contains(@class, 'topic-list-item')]- элемент строки темы со всей информацией, предок первого элемента -
/ descendant::*[contains(@class, 'posts')]- промежуточный элемент-потомок строки, который содержит в себе именно количество ответов (если не брать этот, то в следующем шаге будет коллекция с количеством ответов и количеством просмотров темы) -
/ descendant::*[@class = 'number']- элемент, в котором и содержится нужная нам информация по количеству ответов
Собственно всё по xpath и осям. Надеюсь, этого вам будет достаточно для понимания принципа написания локаторов и хождения по дереву элементов с помощью осей.
2. Отладка локаторов
После того как вы написали локатор до нужного элемента, стоит определиться, что с этим элементом вы хотите сделать:
- кликнуть – самое простое,
_driver.findElement(By.Xpath("ваш xpath")).Click(); - ввести текст или опционально предварительно очистить поле ввода и уже вводить текст:
var element = _driver.findElement(By.Xpath("ваш xpath")).Click();
element.Clear();
element.SendKeys("текст для отправки в поле");
А если вам, наоборот, надо получить какое-то значение со страницы, и конструкция _driver.findElement(By.Xpath("ваш xpath")).Text возвращает пустую строку? В таком случае вам поможет консоль браузера в тех же инструментах разработчика.
Перейдем в google.com, введём в строку поиска текст, найдём локатор и посмотрим, что есть в дереве элементов:

Мы написали локатор, который сейчас однозначно находит строку поиска, но выцепить введённый текст не получится. И кодом через
element.Text получим, скорее всего, пустую строку.Давайте перейдём на вкладку
Console и выполним следующий код:
var elems = $x("//input[@type = 'text']")
elems.forEach(x => console.log(x.innerText))
elems.forEach(x => console.log(x.value))
elems.forEach(x => console.log(x.outerText))
elems.forEach(x => console.log(x.innerHTML))
elems.forEach(x => console.log(x.outerHTML))
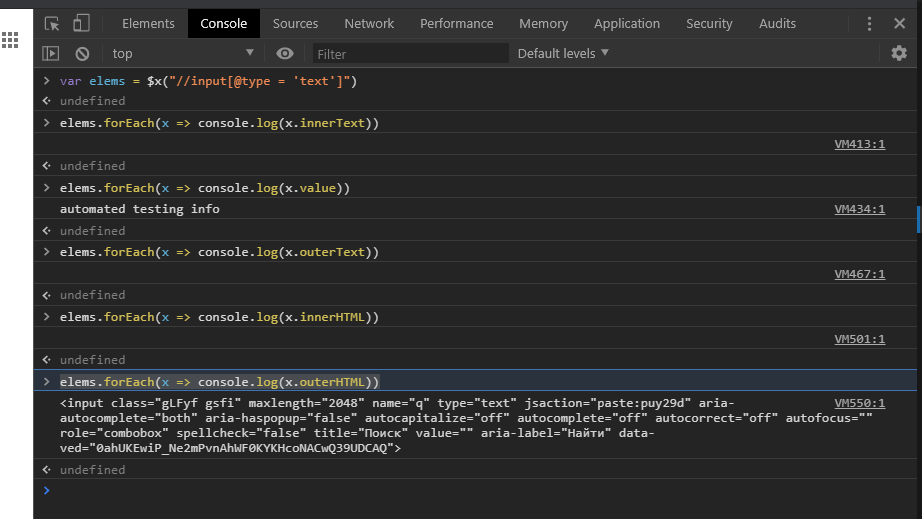
Что мы сделали?
-
var elems = $x("//input[@type = 'text']")– в переменную elems положили все элементы по локатору, или если кодом селениумаvar elems = _driver.findElements(By.Xpath("//input[@type = 'text']")) -
elems.forEach(x => console.log(x.innerText))– для каждого элемента коллекции вывести текст -
elems.forEach(x => console.log(x.value))– вывести текущее значение каждого элемента -
elems.forEach(x => console.log(x.outerText))– чем отличается innerText от outerText сходу не скажу, но порой так можно получить доступ к тексту -
elems.forEach(x => console.log(x.innerHTML))– получить HTML-код всех вложенных элементов в элементы коллекции -
elems.forEach(x => console.log(x.outerHTML))– получить HTML-код самих элементов коллекции и вложенных в них
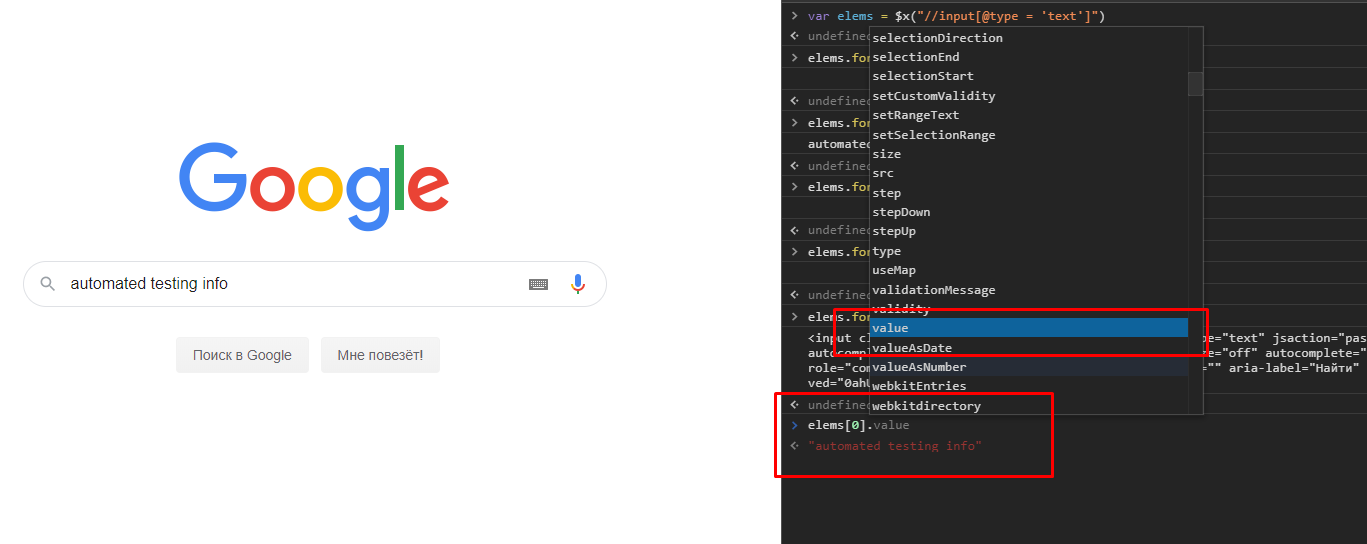
Также можно обратиться к элементу коллекции по индексу и через точку посмотреть, какие свойства и атрибуты доступны:
Если кодом Selenium, то выглядеть это будет так:
var elem = _driver.findElement(By.Xpath("//input[@type = 'text']"));
string text = elem.Text;
text = elem.GetAttribute("value");
text = elem.GetAttribute("outerText");
text = elem.GetAttribute("innerHTML");
text = elem.GetAttribute("outerHTML");
На этом я закончу. Надеюсь, гайд окажется полезным!
Если считаете нужным что-то добавить, пишите в комменты, я добавлю.
