 testomat.io управление авто тестами
testomat.io управление авто тестамиИспользую Selenium Grid для параллельного запуска тестов. Набор инструментов - Java, TestNG,Maven,Jenkins. Есть отдельный сервер приложения, отдельный сервер БД. Сервер CI(Jenkins) находится на сервере приложения. Сервер приложения и сервер БД - виртуальные машины. Есть физические машины - 10 штук. На одной крутится хаб, на 9 - ноды. Тесты идут в 9 потоков. Идут нормально, параллельно. Проблема в том, что скорость выполнения приблизительно равна скорости выполнения если запустить все эти тесты в один поток локально. И так около 9 часов, и так около 9 часов. Параллелизация вроде как бы для ускорения.А по факту ничего кроме лишней головной боли. К сожалению нигде не нашёл никакой информации как понять где узкое место и как понять что изменить чтобы ускорить процесс. И попутно какие требования к ресурсам у хаба? Сколько нодов он может поддержать? Какие ресурсы ему необходимы?
У вас что тесты связаны? т.е. зависимые друг от друга?
Как вы понимаете что тесты выполняются на разных машинах?
А я вижу физически, что они идут на разных машинах. Ну и в консоли грида это тоже заметно. И по отчёту по таймингам. Тесты не связаны.
Такое ощущение, что все тесты запускаются на каждую ноду, а не разделены по группам и каждая нода выполняет только свою группу.
ЗЫ: У меня все тесты выполняются около 2 часов, при распаралеливании в 2 потока на 2 ноды, время выполнения 1ч. 30 минут т.к. есть пересекающиеся и их приходится гнать в одном из потоков 
Очень странная ситуация. Может вы на нодах прогоняете одинаковые тесты? Потому как если из 100 тестов на одной ноде запустить первые 50, а на другой вторые 50 одновременно, то они явно должны быть быстрее. Вторая возможна ситуация, у вас есть один длинный тест, который ранится 7 часов и 99 мелких тестов по 10 сек. естественно что при таком раскладе оно шо так, шо эдак, будет в районе 7 часов ))
Нет. Всё запускается раздельно. Иначе бы в отчёте было в 9 раз больше тестов не так ли?
далеко не факт, если в отчет попадает только последний успешный прогон…
Честно говоря не понял, но не вижу никаких оснований для такой ситуации.
Для проверки запустите только 9 тестов и посмотрите как они сработают.
Да даже 2х тестов в параллели достаточно будет.
Дело в том, что я уже проводил такие эксперименты. Иными словами вы хотите сказать, что если я запущу всё в один поток на одной ноде, то все тесты по этой логике пройдут за то же время - поскольку они у меня одни и те же идут якобы параллельно. Но это не так. Хотя бы потому что локально я их запускаю через driver, а гридом через remote driver, который по умолчанию работает значительно медленнее.Если бы так и было они бы шли совсем не 9 часов, а раза в два медленнее(точнее сказать трудно, но очевидно, что это было бы заметно без всяких дополнительных средств измерения).Я всё-таки думаю тут проблема в ресурсах и самое главное непонятно в каких именно. Увеличить производительность всего сразу к сожалению возможности нет. Непонятно что умирает больше - сервер бд, или сервер приложения, или хабБ или сеть и как это понять. Кроме того интересный вопрос сколько нодов на практике способен поддержать хаб и чем это определяется - нигде не нашёл такой информации(может плохо искал).
А Вы уверены, что само тестируемое приложение (его сервера) тянет 9 потоков тестов?
Что мешает мониторить аппаратные метрики серверов и найти того, кому “плохо” ?
Как раз и не уверен. Мешает неосведомлённость моя в этом вопросе. Подскажите пожалуйста средство мониторинга простое и удобное.
Windows:
Performance Monitor он же Системный монитор он же perfmon
*nix:
top
iostat
vmstat
и подобные команды
Еще лучше - поставить тестовый контур под централизованный мониторинг (Zabbix или что там у вас на Прод среде…)
Спасибо.
- Уменьшу количество нодов до 5
- Вынесу на отдельную машину Jenkins
- Запущу perfmon логирование для сервера приложения, сервера бд, сервера Jenkins, хаба и какого-нибудь нода.
Завтра будет что-то видно.
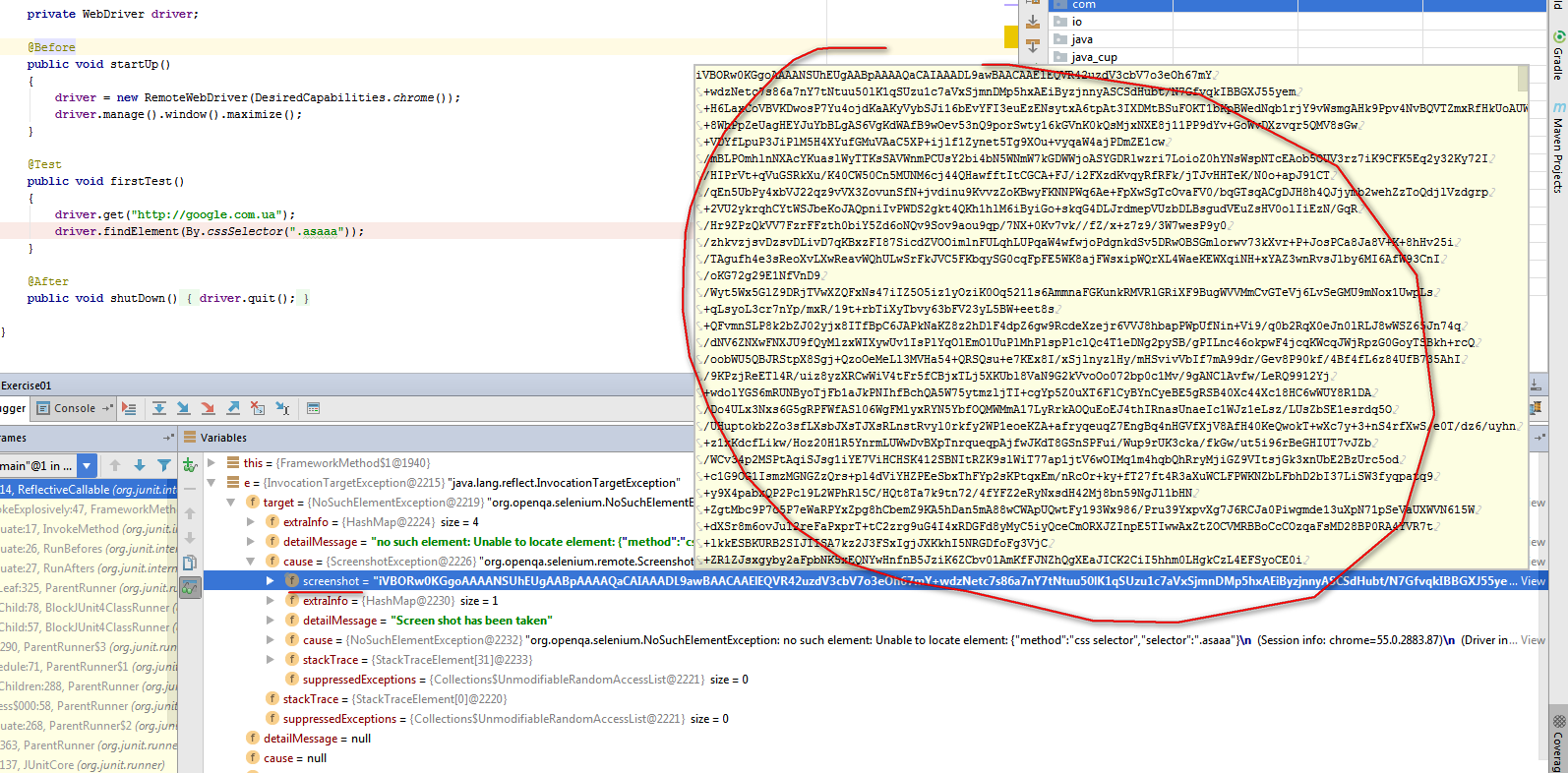
Тут есть один интересный, неочевидный момент. Selenium Server (RemoteWebDriver) при возникновении noSuchElementException всегда пересылает в теле респонса скриншот, даже когда его об этом не просят. Это приводит к тому, что разнообразные проверки на наличие элемента, которые ждут пока он появится и используют для этого метод findElement() генерируют нехилый трафик из скриншотов (особенно когда у нас какой-нибудь FullHD ![]() ).
).
Чтобы этого избежать, в таких местах лучше делать findElements() и проверять, что size() результирующего списка больше нуля. Так как findElements() не кидает исключений (при условии, что локатор синтаксически корректен).
На практике это можно определить только эмпирическим путем. Хотя можете посмотреть про опыт Яндекса в этом деле: Grid Router – scalable and fault tolerant solution for grid
Очень странно. Вы в этом уверенны? Я просто такого не замечал. Да и многие бы уже возмутились таким поведением.
Проверте, поставте брекпоинт в месте, где вы делаете findElement() для несуществующего элемента и посмотрите в объект, который возвращет селениум сервер вместе с ексепшином, там есть инстанс remote.ScreenshotException, который содержит сам скриншот. Чуть позже картинку покажу, пока нет доступа к компу.
Ну так ты запусти не все 9 тыщ а штук 10, посмотри быстрее или нет, посмотри что они “реально иду параллельно”, потом запусти 100 и тд. Может у тебя там везде слипы стоят и как бы до задницы ему эти ваши ускорения. А можем шаринг драйвера наисан не правильно и у вас там Lock, так что тесты вроде как и парралельно, но на самом деле просто некоторые потоки ждут пока другой отпустит драйвер.
Поэкспериментировал.
Начальные условия - 9 потоков, 9 нодов с ограничением maxinstances = 1 Запускать больше 1 на ноде- точно пустая трата времени. Проверено раньше. Они выполняются, но медленне пропорционально количеству инстансов. ОП мало. Chrome. Время выполнения - около 9 часов.
Вариант 1
Сократил количество потоков до 5. Время выполнения увеличилось до 11 часов. Вроде как логично.
Вариант 2
Увеличил количество потоков до 6. Время выполнения - 9 часов. Существенный прирост. Но это так же как и было нв 9 потоков. Боюсь что это максимум. Попробую в 7 потоков при тех же других условиях.
С мониторингом производительности проблема. Настроил мониторинг на сервере приложения, сервере БД. машине где Jenkins и одной из нод. По стандартному шаблону… Два часа генерирует репорт, а потом говорит что не может его отобразить. Я догадываюсь что слишком много данных, надо бы сократить. Буду разбираться.