Добрый день.
Решил попробовать себя в автоматизации.
На данный момент пошел только 7 день
Столкнулся с такой проблемой.
При выполнении запроса с базы
-- coding: utf-8 --
cur.execute(“select city_desc from table1 where rownum = 1 order by dbms_random.value”)
result = cur.fetchall()
получаю ответ в виде
(’"\xe7\xe0\xef\xe0\xf0\xee\xec\xe0\xf0""\xbf\xe2\xea\xe0"’,)
Подскажите как это безобразие можно преобразовать в нормальный вид, имеется ввиду кирилицу, чтобы потом это значение можно было отправить в поле для ввода?
# -*- coding: utf-8 -*-
import cx_Oracle
from os import environ
environ["NLS_LANG"] = "AMERICAN_AMERICA.CL8ISO8859P5"
db = cx_Oracle.connect(login,passw, dsn_tns)
...
cur.execute("select city_desc from table1 where rownum = 1 order by dbms_random.value")
result = cur.fetchall()
print result[0]
при попытке сделать “youstring.decode(“utf-8”)”
result = result.decode("utf-8")
получают ответ
AttributeError: ‘list’ object has no attribute ‘decode’
Я так понимаю, что результат это список, а этот список не имеет такого атрибута.
По идее тогда надо преобразовать в строку, но с этим тоже проблема. Пока не получается, нехватка знаний ((
ну во-первых fetchall возвращает вам так сказать, список списков. во-вторых, вытащите конкретный элемент и выведите его принтом. Если у вас одна строка возвращается по запросу можно сделать как нибудь так:
rows = cursor.fetchall()
united_rows = []
for row in rows:
united_rows.extend(row)
d_row = [s.decode("utf-8") if s else "" for s in united_rows]
for x in d_row:
print x
rows = cur.fetchall()
united_rows = []
for row in rows:
united_rows.extend(row)
d_row = [s.decode("cp1251") if s else "" for s in united_rows]
for x in d_row:
pass
y = x.encode("utf-8")
print y
получил результат такой "ЧРЯРаЮЬРа""чТЪР"
понимаю, что уже близко, но никак не получается … ((
Я правильно понимаю что текст - “Запаромар’ївка” - населенный пункт? Если да, то изначальную фразу “\xe7\xe0\xef\xe0\xf0\xee\xec\xe0\xf0"”\xbf\xe2\xea\xe0" обрабатывайте через decode(“cp1251”).
 testomat.io управление авто тестами
testomat.io управление авто тестами
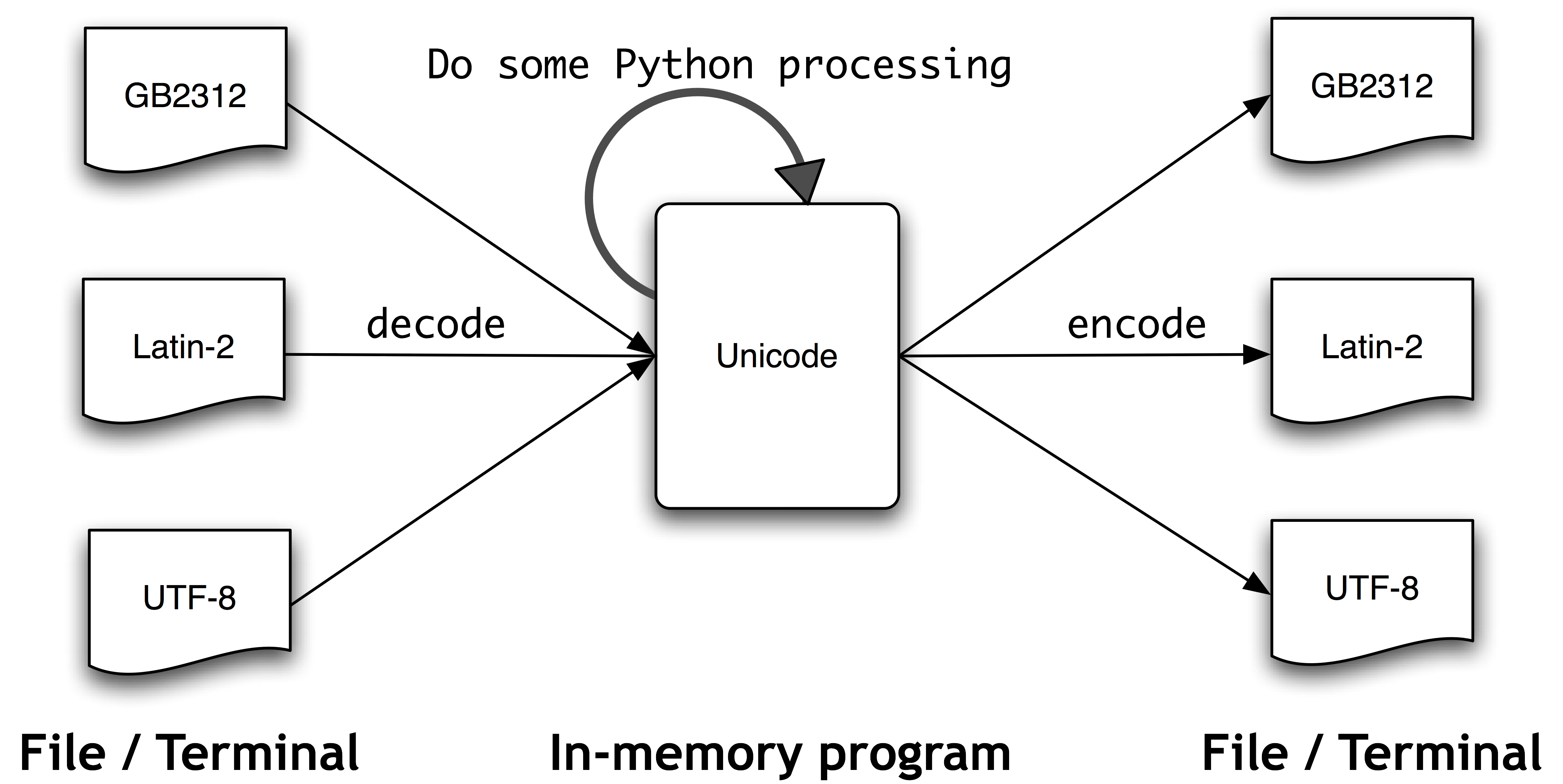

 Как бы было все проще, если бы везде использовали utf…
Как бы было все проще, если бы везде использовали utf…