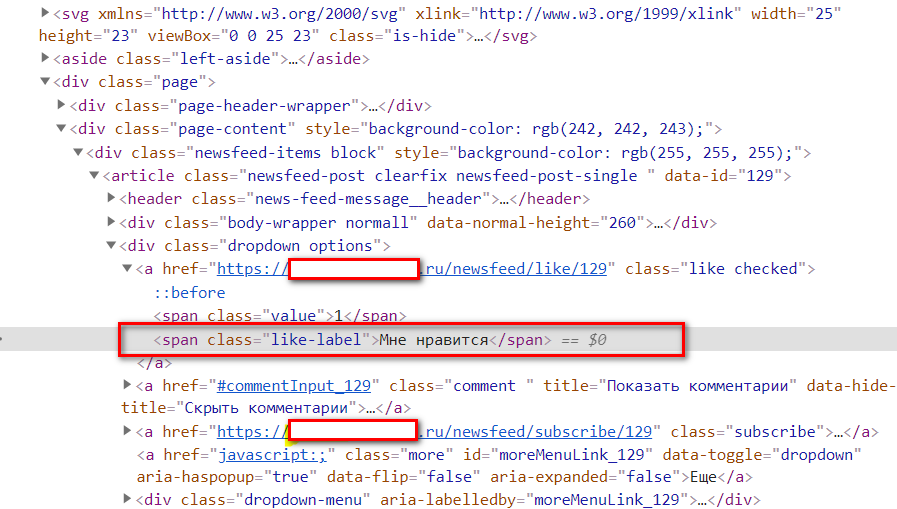
Прошу помощи в вопросе: есть элемент на странице и при запуске теста когда chrome в полноценном режиме, то элемент находится и тест работает в 100 случаях из 100, но если запускаю этот же тест в хроме с режимом headless, то элемент не находится, скажите почему?
Вот сам линк как его ищу:
точно так же, как и без него. здесь же не принципиально в каком режиме браузер запускается. хтмл страницы можно выгрузить и в хедлес и в хедфул. не сильна в питоне, погуглите, я нагуглила эту страницу например, может там есть полезные методы Get HTML source of WebElement in Selenium WebDriver using Python - Stack Overflow
записываете в файлик потом стрингом и читаете после прогона, смотрите что по факту там стоит
Если страница доступна без авторизации и т.д. то поможет cURL. Из консоли Linux\Mac.
curl https://automated-testing.info/
на винде не помню как сделать.
 testomat.io управление авто тестами
testomat.io управление авто тестами