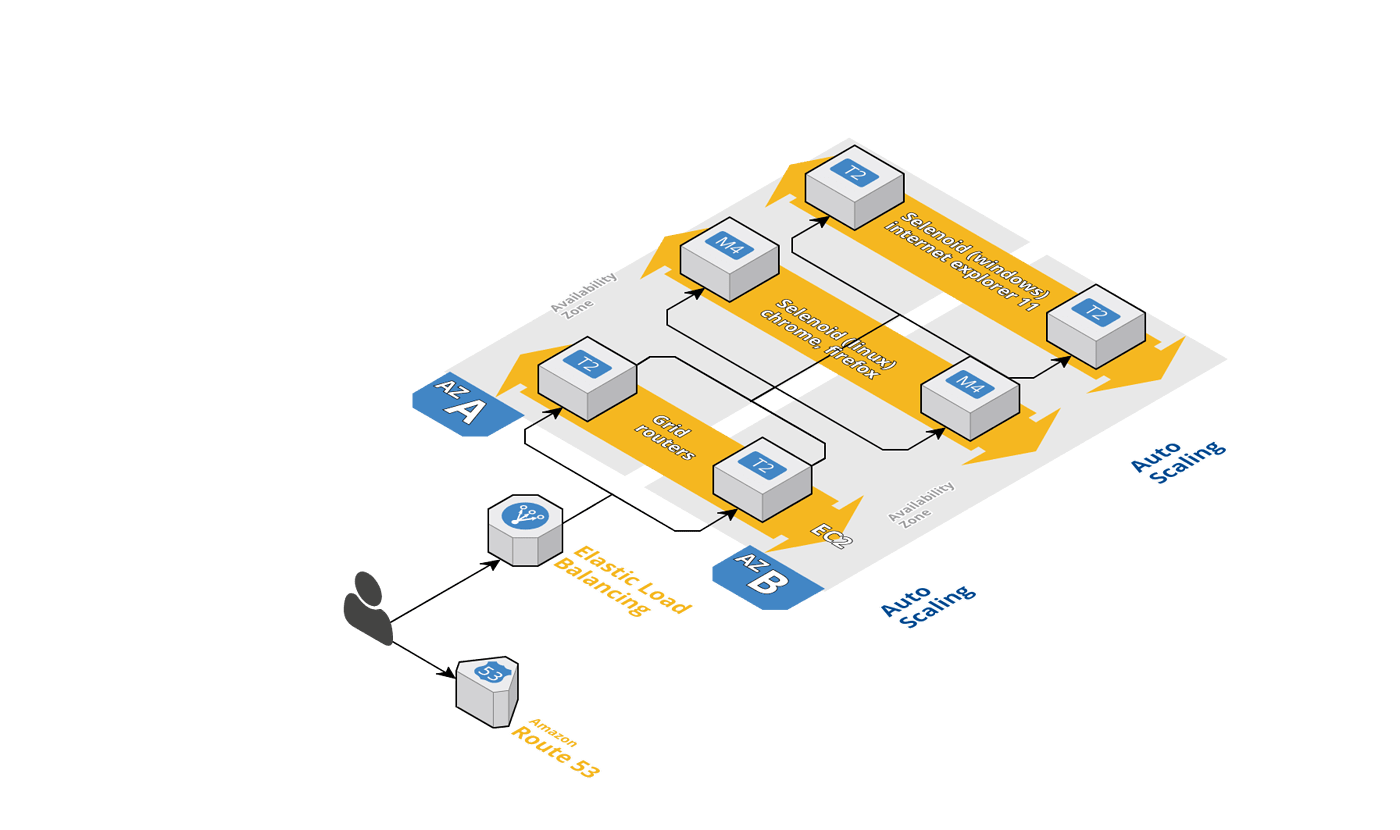
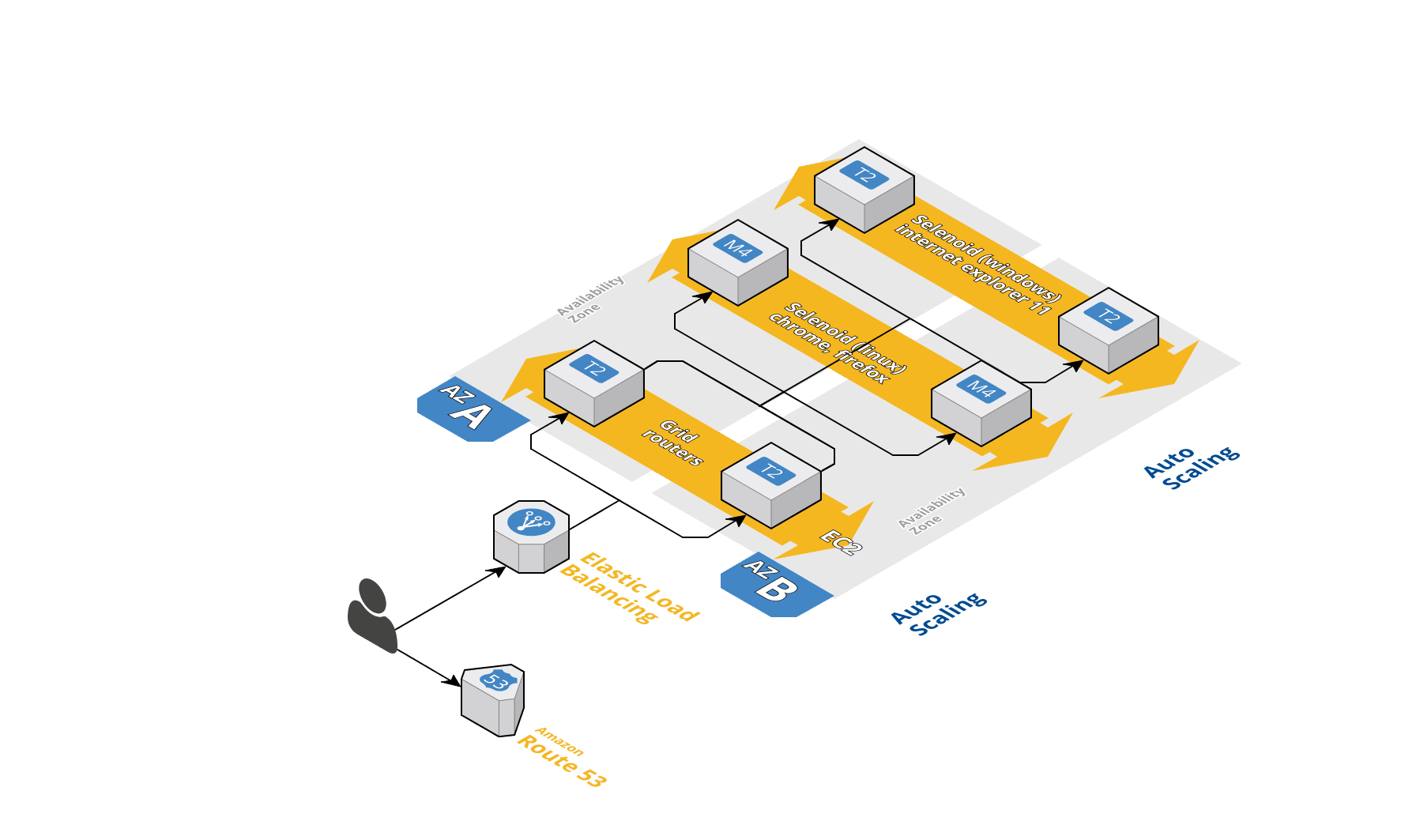
Есть задача, получить легкую маштабируемость для тестов в две сторонах:
По горизонтале - распаралеливать 1 запуск в N паралель для ускорения исполнения. Сейчас запускаем в 3, больше виртуалка не тянет. Хотим в 10, максимум 20. Очень критично.
По верикале - делать N запусков одновременно. Сейчас єто 20, возьмем максимум 50. Менее критично, но также необходимо.
Попробовали selenoid, понраивлось, но он упираеться в мощность одной машини. Хочеться совместить его с ggr, чтоб на многих виртуалках бежало. Есть успешние истории такого? Может какие-то еще совети будут?
AutoScalingGroup for Selenoid linux machines (custom AMI with docker and necessary docker images + browsers.json)
AutoScalingGroup for Selenoid windows machines (custom AMI with pre-configured OS/IE settings)
AutoScalingGroup for GGR instances (currently running with only 1 t2.small instance and successfully serve ~1000 rpm)
Each EC2 instance has datadog agent installed. Selenoid /status endpoint stats are send to Datadog and aggregated there (number of queued, pending, active and total sessions). There are some monitors/alarms set in datadog that we listen to and change DesiredCapacity of appropriate AutoScalingGroup (selenoid-linux or selenoid-windows)
Думаю шаг 4 можно также было бы сделать и с помощью AWS CloudWatch, или другой monitoring/alerting тул.
Относительно вашего вопроса с ECS. К сожалению я даже не знаю как Selenoid подружить с ECS без внесения изменений в исходный код Selenoid (чтобы вместо запуска докер контейнеров с браузерами запускались ECS Task). Потому что если вы сейчас запускаете Selenoid на ECS кластере - то контейнеры с браузерами будут подниматься только на той же машине на которой запущена задача Selenoid-а. И тогда весь смысл “кластера” пропадает…
Сейчас реализовано по-простому (так как всего 1 GGR инстанс, и нет проблем с синхронизацией quota файлов):
на GGR инстансе в кроне каждую минуту запускается Ruby скрипт, который получает на вход имена AutoScalingGroups Selenoid через перменную окружения). В моем случае это 2 группы (1 linux, 1 windows)
# /etc/grid-router/get_quota_xml.rb
require 'aws-sdk'
require 'rest-client'
require 'json'
require 'nokogiri'
AWS_REGION = 'eu-west-1'
SELENOID_PORT = 4444
# comma-separated names of AutoscalingGroups of selenoid instances
ASG_NAMES = ENV['ASG_NAMES'] || raise "ASG_NAMES env var should be defined"
# param asg_names Array of String names of AWS AutoScaling Groups
# return [Array] of private IP addresses of Healthy & inService instances in ASG
def get_ec2_instances(asg_names)
as_client = Aws::AutoScaling::Client.new(region: AWS_REGION)
autoscaling = Aws::AutoScaling::Resource.new(client: as_client)
asg_names.map do |asg_name|
asg = autoscaling.group(asg_name)
ec2_instances = asg.instances.select {|i| i.health_status == "Healthy" && i.lifecycle_state == 'InService' }
ec2_instance_ids = ec2_instances.map(&:instance_id)
ec2_client = Aws::EC2::Client.new(region: AWS_REGION)
ec2 = Aws::EC2::Resource.new(client: ec2_client)
ec2.instances(instance_ids: ec2_instance_ids).map(&:private_ip_address) rescue []
end.flatten
end
# param ec2_instance_ips [Array] of selenoid host IP addresses / FDNs
# return [Hash] of <ip_address> => <response from /status endpoint> pairs
def get_selenoid_configs(ec2_instance_ips)
servers_with_configs = ec2_instance_ips.map do |addr|
{ addr => get_selenoid_status(addr) }
end.reduce({}, :merge).select { |k,v| !v.empty? }
end
def get_selenoid_status(addr)
JSON.parse(RestClient.get("http://#{addr}:#{SELENOID_PORT}/status").body).to_h
rescue Errno::ECONNREFUSED
# Need to reboot selenoid instance in this case
{}
end
# param original_hash [Hash] of <ip_address> => <response from /status endpoint> pairs
# return [Hash] GGR quota configuration in a form of Hash
# than can be easily transformed into quota/<username>.xml
def transform_settings(original_hash)
result = {}
original_hash.each do |ip, settings|
settings['browsers'].each do |browser, versions|
result[browser] ||= {}
versions.each do |version, _|
result[browser][version] ||= {}
result[browser][version][AWS_REGION] ||= []
result[browser][version][AWS_REGION] << { name: ip, port: SELENOID_PORT, count: settings['total'] }
end
end
end
result
end
# return content for GGR quota/<username>.xml (with all available browsers listed)
def build_xml(settings_hash)
builder = Nokogiri::XML::Builder.new { |xml|
xml.browsers('xmlns:qa' => 'urn:config.gridrouter.qatools.ru') {
settings_hash.each do |browser, versions|
xml.browser(name: browser, defaultVersion: max_version(versions.keys)) {
versions.each do |version, regions|
xml.version(number: version) {
regions.each do |region, hosts|
xml.region(name: region) {
hosts.each do |host|
xml.host(host)
end
}
end
}
end
}
end
}
}
builder.doc.tap { |d| d.root.name = "qa:browsers"}.to_xml
end
def max_version(versions)
versions.map {|v| v.to_f}.max.to_s
end
ip_addresses = get_ec2_instances(ASG_NAMES.split(','))
raw_selenoid_statuses = get_selenoid_configs(ip_addresses)
json_settings = transform_settings(raw_selenoid_statuses)
xml_config = build_xml(json_settings)
# write xml config to STDOUT
puts xml_config
Если же у вас более 1 GGR за LB - то мое решение вам не подойдет. Я бы смотрел тогда в сторону Amazon EC2 Auto Scaling lifecycle hooks - Amazon EC2 Auto Scaling (реагировать на изменения в AutosclaingGroup и через свою Lambda-функцию обновлять квоту). Правда не уверен, что это будет надежнее…
Це було зроблено майже через місяць після питання, а потім ми скейлились і скейлились:-)
Висновок:
1 ggr (не прийшлось додавати ще, працював разом з одним селеноід хостом і не віджирав ніколи більше пару мегабайт)
10 селеноід віртуалок - на кожній селеноід контейнер і від 6 до 16 можливих браузер контейнерів). Починали з 3 віртуалок і 32 браузерів. Потім, додаєш віртуалку з селеноїдом, grace restart ggr і побігли:-)
до 150 браузерів в паралель
Одного разу GGR+all Selenoids не рестартувались 9 місяців, дуже стабільна і самодостатня система.
Важливо, контейнера дають приріст по пам’яті, але не по CPU. Ми знайшли оптимальний баланс по перформансу коли 1 браузер контейнер = 1 ядро CPU. У вас це може бути по іншому, експереминтуйте:slight_smile:
 testomat.io управление авто тестами
testomat.io управление авто тестами