 testomat.io управление авто тестами
testomat.io управление авто тестамиДобрый день! Использую Selenium WevDriver + C# (VisualStudio). Не получается вытащить текстовые значения из Html страницы. Сначала нахожу его через XPath как вэб-элемент, затем пытаюсь преобразовать в string и достать из него сам текст (может существует способ проще с применением contains()), чтобы потом работать с циклами. Последний код выдаёт пустое значение, вместо “Прогноз оправдался”.
IWebElement POprav = Browser.FindElement(By.XPath("//*[@id=‘deal_list’]/table/tbody/tr[1]/td[8]/span"));
String Chet = POprav.GetAttribute(Text);
Как достать текст и дальше работать с ним в циклах? Как сделать что-то подобное для второго кода (“1 279, 00”)?
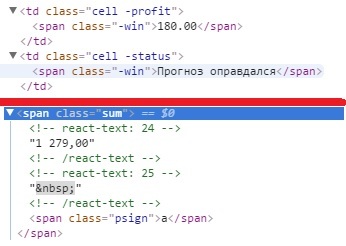
Попробуйте String Chet = POprav.Text;
1 лайк
GetAtribute(“class”)
Всё заработало! выдаёт нужные и правильные элементы!
Большое спасибо, помогли начинающему вэб-тестировщику)