Здравствуйте коллеги! Смотря документацию Selenide у меня сложилось впечатления что можно искать child элементы в parent элементе указывая только адрес child элемента, как показано тут:
т.е., как я понимаю, данная строка ищет ‘menu’ и ‘.item’ только внутри ‘header’, а все прочие ‘menu’ и ‘.item’ элементы на странице, не являющиеся child’ами ‘header’ будут проигнорированы?
Пробую применить у себя:
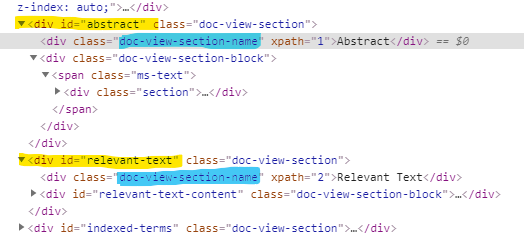
на странице есть блоки у которых есть child элементы с одинаковым названием html классов в каждом блоке:
Хочу скажем проверить наличие каждого блока и текст заголовка в нем:
первая строчка еще сработает т.к. блок Abstract идет первым и $x("//[@class=‘doc-view-section-name’]") берет значение у первого найденного элемента, а вот вторая уже даст fail т.к. $x("//[@class=‘doc-view-section-name’]") по-прежнему возвращет значение первого найденного элемента на странице а не элемента внутри $(byId(“relevant-text”)).
Вот хочется понять, я неправильно понимаю как это работает или не правильно делаю?
[dzyof], спасибо!
Идея была еще и в том чтобы разделить parent и child элементы например для случая когда parent’у тоже нужны какие-то проверки. Да, с css локаторами все работает:
 testomat.io управление авто тестами
testomat.io управление авто тестами