 testomat.io управление авто тестами
testomat.io управление авто тестамиWebdriver + python
Здравствуйте! Я в этой теме новичок и прошу помощи.
Задача состоит в следующем:
На сайте мне нужно отобрать все ссылки которые перенаправляют на другую веб-страницу и произвести над ними определенные действия. Делаю я это с помощью driver.find_elements_by_tag_name("a"). но на сайте есть также ссылки на файлы (*.doc, *.xls, *.pdf и т.д.) Вопрос в том как мне отделить ссылки на файл от обычных ссылок?
Я пытаюсь решить эту проблему следующим образом - вытаскивать атрибуты “href” и проверять строку на наличие символов “.doc”, “.xls”, “.pdf” и т.д. но это как-то громоздко и не очень удобно.
Может кто знает как это решить средствами Webdriver или JavaScript? или может кто-то предложит более “элегантный” способ?
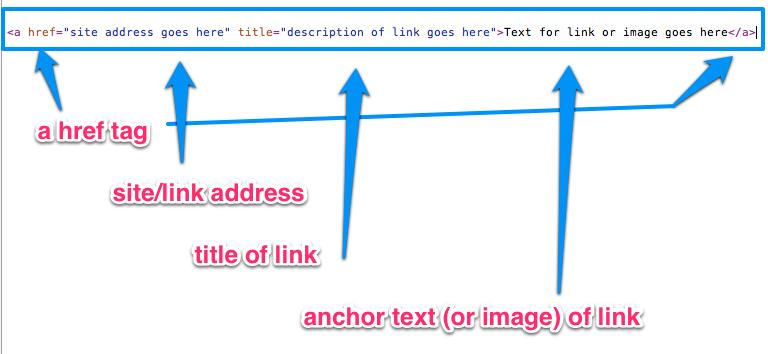
Гляньте сюда:
1 лайк
или через css selectors
findElements(By.cssSelector("a[href*=.doc]"));
1 лайк
Спасибо. Я воспользуюсь связкой “not contains” мне xpth более ближе. Это будет удобнее чем все ссылки перебирать))) Но все же не очень удобно прописывать все расширения файлов.
через and можно сборное условие сделать:
.//a[not(contains(@href, ".png")) and not(contains(@href, ".jpg")) and not(contains(@href, ".gif")))]
1 лайк
Пока что нашел такой вариант через библиотеку на питон urllib3:
import urllib3 http = urllib3.PoolManager() res = http.urlopen("GET","https://pypi.python.org/pypi/urllib3/1.12") typ = res.headers['Content-Type']
Если переменная typ возвращает text/html то значить это веб-страница, если что-то другое то пропускаем.
В css3 :not есть, и поиск в конце через $= : By.cssSelector(“a:not([href$=‘.doc’]:not([href$=‘.xls’])”)
1 лайк
Мысль правильная, решение правильное (лучше чем по расширению файла парсить). Но маймов для текста существует больше: Complete MIME Types List - FreeFormatter.com
У мсдн есть упрощенный список Content-Type: text | Microsoft Learn
Спасибо, полезная вещь, в будущем думаю пригодиться. А в текущей задаче мне будет достаточно text/html. т.к. насколько я понял все *.htm, *.html, *.php возвращают именно text/html.
Нет, зависит от настроек сервера.
То есть при определенных настройках сервера, Content-Type у файла *.html может быть не равен “text/html”?
Да, любое расширение можно отдать клиенту с каким угодно content type.
Ясно, спасибо.
Но, я думаю, такой вариант возможен при явном желании выдать ложные данные. Надеюсь в рамках проекта этого не будет)