И дальше нужно ее переодически обновлять( раз в 5 сек на протяжении минуты) и если на ней что-то поменялось(первая строчка допустим стала 4 links) то тест проходит, если на протяжении минуты ничего не поменялось - то фейлим тест
Сохраняете html страницы в файл либо переменную. Например, currentHtml
Создаёте wait = new WebDriverWait(driver, 60, 5000), где 60 максимальное время ожидания в секундах, а 5000 периодичность проверки в миллисекундах
Ждете wait.until ( new Predicate(){ @Override
public boolean apply(WebDriver driver){
// Повторно считываете html в другую переменную. //Например, newHtml и сравниваете
return currentHtml != newHtml;
}
});
Если за указанное время html страницы не поменялся, то тест завалится с timeOutException
P.S. в коде могут быть синтаксические ошибки. Пишу с мобильного нет возможности перепроверить.
Очень странный тест, но раз нужно, воспользуйтесь циклом for в роботе, за количество итерации возьмите время максимального ожидания до фейла разделённого на примерное время которое уходит на загрузку страницы и проверку. В цикле сравнивайте заранее сохранённое значение перед циклом со значением полученным в цикле. Если совпадает выходите из цикла и измеряйте флаг проверки на true (по умолчанию он выставлен в false). А после цикла уже проверяйте флаг на тру. Если не тру фейлите тест. Все довольно просто. Как фейлить тест и делать циклы описано в документации к роботу
P.S.: если не хочется писать такую лапшу на роботе, всегда можно написать это на Python в виде библиотеки
Спасибо за советы.
Все получилось, скрипт работал с обычной штмл страницей в которой было 5 строчек, но когда пытаюсь его использовать на тяжелой странице(с таблицами, кучей линков и кнопок) то фейлится.
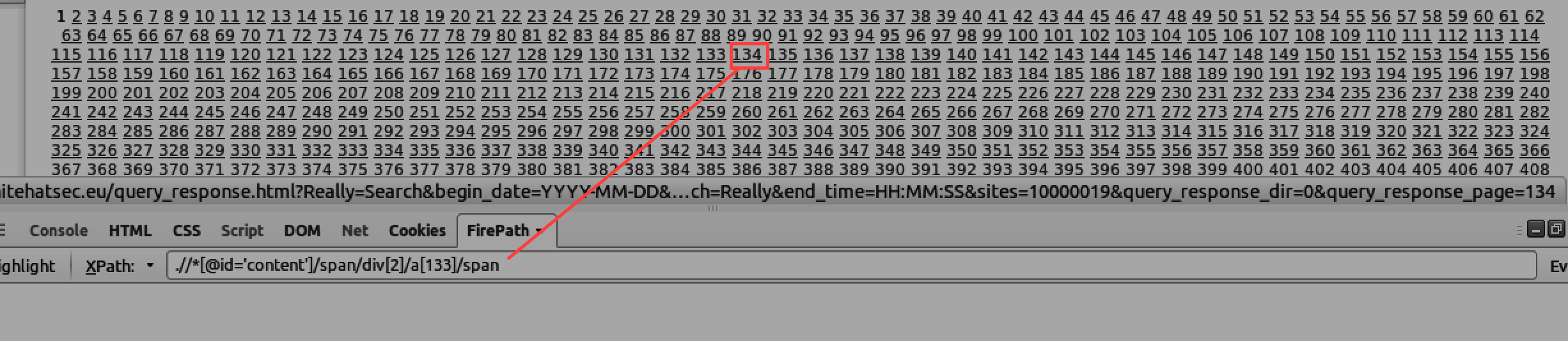
Застрял вот в чем: Загружаю страницу - на ней много елементов - меня интересуют номера страниц, которые при каждой перезагрузке будут увеличиваться.
Я подумал что было бы хорошо использовать Get Matching Xpath Count который посчитал бы сколько сейчас на странице кнопок, после перезагрузки страницы посчитал бы еще раз.
Но не могу написать правильный икспасс - тест зависает в этом месте на долго и фейлится.
Могли бы вы помочь написать правильный икспасс который подошел бы ко всем номерам страниц?
Не совсем понял, что должен найти xpath? Уточните. Конкретный номер страницы или все номера? Как в тесте будет использоваться то, что он найдет? И не плохо бы для экспериментов приатачить к теме html код страницы с номерами
 testomat.io управление авто тестами
testomat.io управление авто тестами