задача:
На открытой странице в секции ‘Response’ во вкладке JSON проверить:
параметр ‘processor’ содержит значения ‘AMAZON’ и ‘RACKSPACE’
на уровне ‘format’ параметр ‘status’ равен ‘Status’
на курсах, спасибо преподавателям, много узнал и, надеюсь, многому научился… но вот такого рода задачи не проходили.
подскажите, как сие сделать? какие темы изучить, чтобы понять как в питоне сделать данную проверку.
Спасибо
регулярка-то здесь зачем?
берём словарик resp_dict = json.loads(response) начинаем смотреть на нужные элементы.
проверка для ‘AMAZON’ и ‘RACKSPACE’
Типа такого:
try:
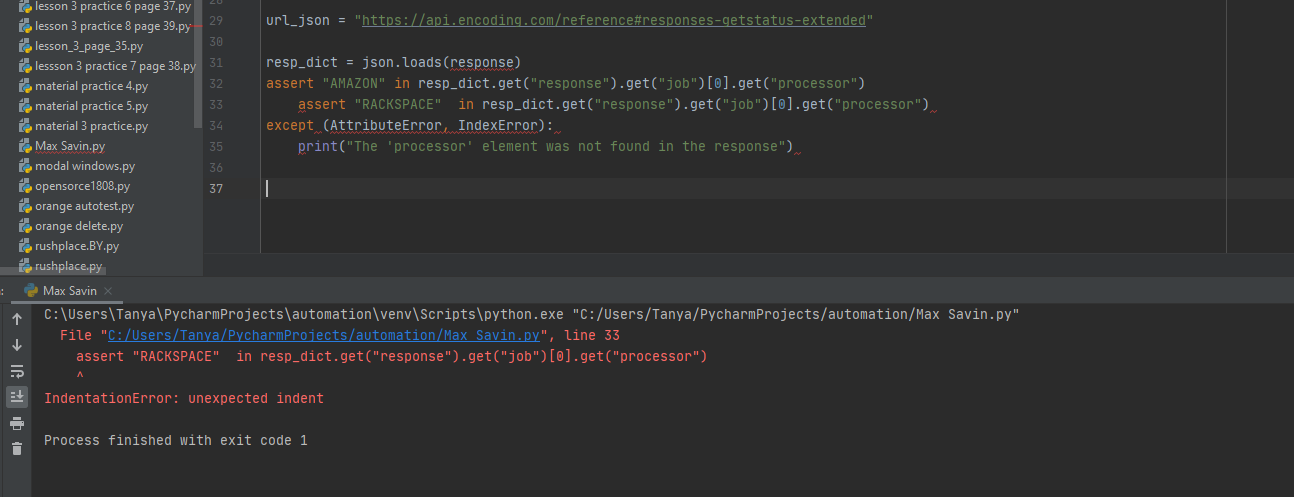
assert "AMAZON" in resp_dict.get("response").get("job")[0].get("processor")
assert "RACKSPACE" in resp_dict.get("response").get("job")[0].get("processor")
except (AttributeError, IndexError):
print("The 'processor' element was not found in the response")
Ругается из-за овериндентации, потом будет ругаться из-за отсутствия try
Касательно вопроса: задача вам не по зубам, если нет сил разобраться с pip и на глаз увидеть овериндент.
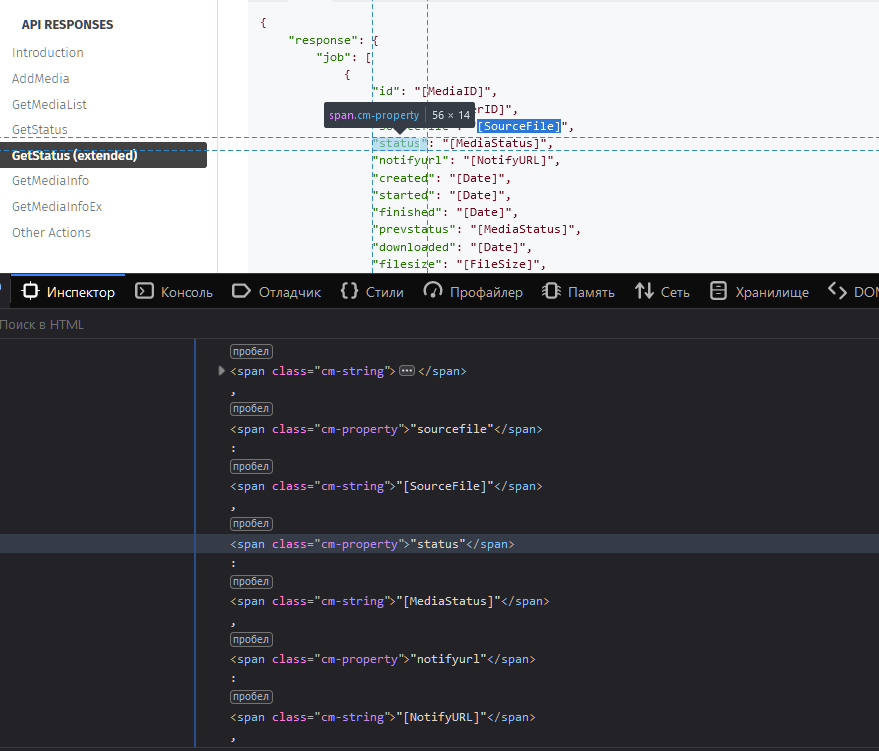
Касательно решения: получить исходник через requests можно, но построить из него вменяемый DOM не выйдет в этом случае. Надо смотреть в сторону костылей вроде BeautifulSoup, Selenium, Grab (последний - не факт), получать элемент по xpath //code[@class="rdmd-code lang-json"] и дальше итерироваться по наследникам, т.к. элементы в блоке кода это не просто форматированный текст (см.скриншот)
я понимаю, что задача не по зубам… к сожалению… возможности самообучению есть только такие… вот и пытаюсь грызть задачи… и искать решения…
спасибо большое за помощь.
Это не самообучение, это извращение, попытка играть в высшей лиге с низкой базы
Dive Into Python или Learning Python Лутца - это самообучение, и серьезный фундамент
Про over-индентацию уже выше объяснили.
Но есть ещё ньюанс: мой пример кода - очень примитивный, работающий “в лоб”, рассчитанный на то, что response - это чистый JSON. Если надо выдернуть этот json из страницы, то, как опять же, ответили выше - нужны другие инструменты.
И, без обид, но в данном случае перед тем, как писать код, нужно понять, как он будет выполняться. Ну, то есть, сначала надо получить данные на вход: откуда они будут браться, в каком виде они будут приходить, кто их будет стягивать? (в моём кусочке кода - никто Он только обрабатывает JSON).
 testomat.io управление авто тестами
testomat.io управление авто тестами
 Он только обрабатывает JSON).
Он только обрабатывает JSON).