testomat.io управление авто тестами
testomat.io управление авто тестамиДанная статья будет несколько отличаться от оригинала на буржуйском, ибо одну и ту же мысль все же можно преподнести под разным углом. Но суть постараюсь не коверкать. ![]()
Java 8 уже достаточно давно в ходу, но ввиду масштабности изменений, периодически приходится открывать для себя что-то новое и интересное.
Совсем недавно наконец дошли руки до более детального рассмотрения нововведений в интерфейсах, на первый взгляд - весьма сомнительных. Для тех, кто не в курсе, в восьмерке появилась возможность задания, так называемых, default methods.
В предыдущих версиях Java common формат интерфейса был следующим:
public interface Sized {
int size();
}
При этом, в момент его подключения к какому-либо классу, заключался жесткий контракт на реализацию приведенных в интерфейсе методов.
public class Basket implements Sized {
private List<Fruit> fruitsList = new ArrayList<>();
public addFruit(Fruit fruit) {
fruitsList.add(fruit);
}
public int size() {
return fruitsList.size();
}
}
В Java 8 концепция значительно изменилась: так называемые дефолтные методы теперь могут иметь тело - конкретную дефолтную реализацию. Причем, связанный с интерфейсом класс совсем не обязан переопределять подобные методы. Более того, мы сможем вызывать их напрямую, как неотъемлемую часть класса.
public interface Sized {
int size();
default boolean isEmpty() {
return size() == 0;
}
}
При этом, наш класс все так же обязан реализовать прототипы, но вот к дефолтному мы можем получить доступ совершенно безболезненно, ничего не переопределяя (хоть такая возможность и есть).
public class Basket implements Sized {
private List<Fruit> fruitsList = new ArrayList<>();
public addFruit(Fruit fruit) {
fruitsList.add(fruit);
}
public int size() {
return fruitsList.size();
}
public boolean isBasketEmpty() {
return isEmpty();
}
}
Возникает теперь логичный вопрос: когда и зачем это нужно? Ну вот представьте, что вы разработчик какой-то популярной библиотеки, к примеру, Selenium. И вот в один прекрасный солнечный день вы захотели расширить возможности WebDriver'а, определив в нем какой-нибудь принципиально новый ноу-хау прототип. К чему бы это привело в Java < 8 версий? Вам пришлось бы перелопатить все классы, реализующие данный интерфейс, добавив соответствующую ноу-хау реализацию. С дефолтными методами восьмерки вы сможете реализовать нужную функциональность в самом драйвере, не затронув при этом ничего лишнего. Проапдейтить можно будет лишь тот класс, которому нужна будет эта фича. Ну или, к примеру, такая фича планируется на будущее, но заложить основу в виде опционального метода вы захотите именно сейчас:
default void coolFeature() {
throw new UnsupportedOperationException();
}
Таким образом, те, кому нужно будет, в свое время просто переопределят этот метод со своей кастомной логикой. Остальные будут жить так, как будто ничего принципиального нового и не произошло.
К слову, стандартный джавовский List был таким же образом расширен дефолтным методом sort, дабы из коробки предоставлять возможность сортировки. А теперь представьте, что было бы в версиях < 8 с таким апдейтом?
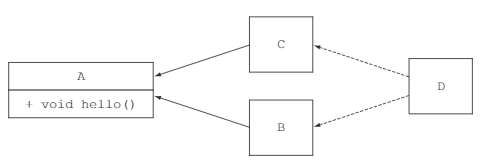
Общая идея и назначение я думаю ясны. Но возникает другой вопрос: чем же интерфейсы в таком случае будут отличаться от абстрактных классов? Ну, во-первых, интерфейсы по-прежнему не могут хранить состояние, в отличие от тех же абстрактных классов. Хотя теперь, они напротив могут задавать некое дефолтное поведение. Во-вторых, ограничение на кол-во прямых родителей / наследников у классов как было единицей, так и осталось. Но вот интерфейсов то мы всегда могли имплементить сколь угодно много. И вот он - самый главный чит восьмерки - теперь у нас есть возможность практически полноценного множественного наследования!
Представьте, что вам нужно логически связать воедино несколько компонентов, которые не имеют прямой связи друг с другом, но призваны решать какую-то глобальную задачу. Раньше это было весьма проблематичным, но теперь стало вполне реальным.
Давайте рассмотрим более осязаемый пример, связанный с нашей непосредственной деятельностью. Предположим, что у нас есть уже какая-никакая архитектурная связка аля BaseTest → Tests и BasePage → Pages. Предположим также, что мы хотим довести тесты до такого уровня, чтобы в них не было ни единой low-level составляющей. Никаких фабрик, промежуточных переменных и т.п. Только чистый DSL. При этом, не стоит забывать и о качественных репортах.
Возьмем, к примеру, тот же Allure, который реализует прекрасный steps logging механизм. И если с common степами все ясно - они располагаются на уровне пейджей, то что делать с ассертами? Допустим, в среднестатистическом тесте у нас может быть >1 проверки. Т.е. логично было бы увидеть в репорте не просто результат assertEquals(actual, expected, message), а что-то по типа Verify that '{2}' is '{1}', где вместо плейсхолдеров будут поставлены, к примеру, message и expected result. При этом, что самое важное, мы сможем четко увидеть, на каком шаге осуществлялась данная проверка.
К сожалению, аннотировать метод внутри метода мы не можем. Исходников у нас тоже нет. Идеи? Можно конечно создать utility class - обертку над ассертами, или открыть конвейер кастомных матчеров. Оценить целесообразность, эффорт или архитектурную целостность данных подходов я предлагаю вам самим.
Здесь же мы рассмотрим еще один вариант, связанный с нашей непосредственной темой - дефолтными методами.
Вот так, к примеру, будет выглядеть наш подопытный тест гугл авторизации:
public class AuthorizationTests extends BaseTest {
@Test
public void correctLoginIntoGooleAccount() {
loadUrl("https://accounts.google.com")
.setEmail("email")
.clickNext()
.setPassword("password")
.staySignedIn(false)
.signIn();
assertEquals(homePage().getUsername(), "Sergey", "Username");
}
}
Откуда взялись loadUrl() и homePage() история пока умалчивает. Пока же, давайте сконцентрируемся на ассерте, а точнее - на его декорировании, приведении к формату, удобному для логирования.
Как вы уже догадались, создавать мы будем не utility класс, и даже не матчер, а всего лишь интерфейс. Обзовем мы его Validator.
public interface Validator {
@Step("Verify that \"{2}\" = \"{1}\".")
default void verifyTextEquals(String actual, String expected, String message) {
assertEquals(actual, expected, message);
}
}
Как мы видим, валидатор наш делает ровно то же самое - ассертит результат. При этом, ввиду того, сам assert был обернут, это дает нам полное и безоговорочное право отмаркировать соответствующий метод в качестве степа, что в последствии будет отображено в репорте. Теперь давайте посмотрим на преображенный тест:
public class AuthorizationTests extends BaseTest implements Validator {
@Test
public void correctLoginIntoGooleAccount() {
loadUrl("https://accounts.google.com")
.setEmail("email")
.clickNext()
.setPassword("password")
.staySignedIn(false)
.signIn();
verifyTextEquals(homePage().getUsername(), "Sergey", "Username");
}
}
Практически ничего не изменилось, за исключением того, что наш класс заключил договор с интерфейсом валидатора. Но ввиду наличия лишь дефолтного метода, реализовывать в самом тесте нам ничего не придется. Да и вызывать verifyTextEquals теперь можно напрямую, как-будто он находится непосредственно в тесте или классе-родителе. При большом желании, если дефолтной валидации нам не будет хватать, мы всегда сможем ее переопределить. Весьма интересно, не так ли?
Поехали дальше… Теперь перейдем к более болезненному вопросу - фабрикам. Если в случае с FindBy + WebElement все предельно очевидно - вызываем PageFactory.initElements и радуемся жизни, то в случае с By не все так гладко. С одной стороны, от нас не требуется рефлективной инициализации элементов, ввиду использования механизма отложенного поиска. Т.е. бери, создавай себе new LoginPage(), и вперед. Но тут же возникает множество вопросов:
- А нужно ли нам многократно плодить новые объекты, пользуясь прямым вызовом конструктора пейджи в качестве возвращаемого объекта?
public HomePage signIn() {
return new HomePage();
}
- Если мы используем отложенный поиск, почему бы не кешировать страницы в пределах конкретного теста?
- Т.е. получается нам нужна кастомная фабрика, но действительно ли мы хотим оборачивать все через reflection?
- Хотим ли мы в тестах сохранять промежуточное состояние пейджей для последующей верификации? Если нет, то где хранить пейдж геттеры.
- Ну и на засыпку вопрос, не связанный с фабрикой, но который вечно намекает на какую-нибудь совсем нелогичную костыльную реализацию: где и как описывать метод первой навигации на наш сайт, при этом возвращающий некий
LoginPage? Ведь фреймворк по сути ничего не знает ни о каких пейджах, кроме абстрактной. Прямо в тесте будем кастить результат? Или сделаем егоstatic void, без привязки к домену?
Итак, давайте по-порядку. Ниже я приведу пример “лобового” подхода к созданию фабрики с возможностью переиспользования страниц. Естественно в контексте нашей темы интерфейсов. ![]() Никаких рефлекшенов, лишь синтаксический сахар для приведения теста и близлежащих компонентов к максимально удобоваримому виду. Все прелести рефлексии я оставил на вторую часть сей статьи.
Никаких рефлекшенов, лишь синтаксический сахар для приведения теста и близлежащих компонентов к максимально удобоваримому виду. Все прелести рефлексии я оставил на вторую часть сей статьи. ![]()
Начнем мы пожалуй с BaseTest класса, который на начальных этапах идеально подойдет в качестве хранилища пейджей.
public abstract class BaseTest {
private static final ThreadLocal<Map<GenericPage, BasePage>> PAGES =
new ThreadLocal<Map<GenericPage, BasePage>>() {
public Map<GenericPage, BasePage> initialValue() {
return new HashMap<>();
}
};
@AfterMethod
public void tearDown() {
cleanUpPages();
}
public static Map<GenericPage, BasePage> getPages() {
return PAGES.get();
}
private void cleanUpPages() {
if (!isEmpty(getPages())) {
PAGES.remove();
}
}
}
Сразу замечу, что драйвера в текущих абстрактных примерах не будет. Только теория, только хардкор. ![]() Сам код предельно прост. Создаем потокобезопасный контейнер, в котором в качестве значений будут храниться интстансы самих пейджей, а ключики… ключики - некоего секретного (пока) типа. При этом, не забываем об автоматической очистке коллекции по заданному условию (в нашем случае это
Сам код предельно прост. Создаем потокобезопасный контейнер, в котором в качестве значений будут храниться интстансы самих пейджей, а ключики… ключики - некоего секретного (пока) типа. При этом, не забываем об автоматической очистке коллекции по заданному условию (в нашем случае это @AfterMethod). Предполагается, что каждый тест будет иметь свой собственный девственный контейнер.
Теперь посмотрим, что же из себя представляет ключик. Как вы уже наварное догадались, это конечно же тип интерфейса уровня фреймворка.
public interface GenericPage {
static BasePage getPageObject(final GenericPage page) {
getPages().putIfAbsent(page, page.create());
return getPages().get(page);
}
static void navigateTo(final String url) {
try {
// handles navigation logic
} catch (Exception e) {
throw new AssertionError("Unable to access the following URL: " + url, e);
}
}
BasePage create();
}
В отличие от своих предыдущих коллег, внезапно, у него отсутствуют дефолтные методы. Но зато мы увидели, каким еще образом можно задавать методы с телом - посредством статики.
Собственно на этот интерфейс мы возложили следующее логическое бремя:
- Специализированный геттер имеет 2 функции: помещение страницы в контейнер и возврат непосредственного инстанса наружу. Магия пока что не очень проясняется, ибо мы используем тип рассматриваемого интерфейса в качестве ключа. Со значением вообще ахтунг, т.к. оно получается путем вызова абстрактного метода того же интерфейса от пришедшего извне параметра. Просто разрыв шаблонов, не так ли?
 Терпение, скоро все встанет на свои места.
Терпение, скоро все встанет на свои места. - Ключ к избавлению от костыльной навигации будет зарождаться в методе
navigateTo, который как вы уже догадались призван (в будущем) взаимодействовать непосредственно с драйвером. - Абстрактный метод
create, имеющий более привычный по ранним версиям Java вид, создает жесткий контракт с имплементирующим классом. Т.е. в момент помещения в мапу, будет вызвана его высокоуровневая реализация.
Теперь же давайте соберем весь пазл по кусочкам в так называемом PageObjectsSupplier интерфейсе.
public interface PageObjectsSupplier {
enum PageObject implements GenericPage {
LOGIN {
public BasePage create() {
return new LoginPage();
}
},
HOME {
public BasePage create() {
return new HomePage();
}
}
}
@Step("Open browser and type the following URL: {0}")
default LoginPage loadUrl(final String url) {
navigateTo(url);
return loginPage();
}
default HomePage homePage() {
return (HomePage) getPageObject(HOME);
}
default LoginPage loginPage() {
return (LoginPage) getPageObject(LOGIN);
}
}
На первый взгляд, ничего сверхъестественного, не так ли? Объясняю… Внутри интерфейса создается enum PageObject, реализующий наш низкоуровневый интерфейс GenericPage (тем самым, мы разрешаем трактовать непосредственные константы PageObject'a в качестве типа интерфейса при передаче в глубину пищеварительной цепи фреймворка). При этом, в качестве констант выступают имена страниц. Но вместо задания привычных нам параметров, каждая константа обязана по контракту реализовать тот самый, ранее упомянутый, метод create. Итого, как только будет вызван метод getPageObject, вместо абстрактного метода будет подставлен один из перечисленных в enum, в зависимости от переданного ключа. Сразу напрашивается вопрос: зачем так сложно? Почему нельзя было просто геттерами возвращать new LoginPage() и т.п. На самом деле конечно можно было. Но из постановки задачи то следовало, что мы не хотим каждый раз создавать новый инстанс, а напротив - переиспользовать уже существующий. Помимо этого, было бы не совсем корректно переносить сторэдж на уровень домена. В итоге, посредством связывания двух интерфейсов разных уровней мы достигли полной инкапсуляции технических деталей получения и хранения страниц от доменного слоя. При этом, дефолтные пейдж геттеры - весьма опциональны и предназначены лишь для того, чтобы добавить синтаксического сахара. К примеру, чтобы не звать напрямую низкоуровневый геттер с ручным приведением типов. Это и есть ответ на вопрос, откуда взялся homePage() при вызове ассерта в рассмотренном выше тесте. Тут же мы видим и наш магический навигационный костыль метод loadUrl, обернутый доменной составляющей, и отмаркированный в качестве степа.
Итак, все, что от нас теперь требуется, - подключить PageObjectsSupplier к тесту. И, о магия, наш тест уже реализует целых 2 интерфейса, в каждом из которых содержится своя уникальная дефолтная логика, облегчающая нам жизнь при написании новых тестов. В качестве последнего штриха, можно объединить оба интерфейса под одним более общим названием TestCase, дабы сократить количество набираемых символов при создании новых классов. ![]()
public interface TestCase extends Validator, PageObjectsSupplier {
}
Ну и конечно же итоговый вариант теста:
public class AuthorizationTests extends BaseTest implements TestCase {
@Test
public void correctLoginIntoGooleAccount() {
loadUrl("https://accounts.google.com")
.setEmail("email")
.clickNext()
.setPassword("password")
.staySignedIn(false)
.signIn();
verifyTextEquals(homePage().getUsername(), "Sergey", "Username");
}
}
Разве не к такому формату мы всегда стремились, придумывая PageObject / DSL и т.п.? И тут дело даже не конкретных рассмотренных выше примерах, ведь предела улучшениям не бывает. Дело в самой концепции, которая развязывает нам руки при решении задач группировки и построения связей между различными компонентами системы. Нам дали еще бОльшую свободу действий, почему бы этим не пользоваться?! ![]()
К слову, вот так будет выглядеть репорт для нашего теста:
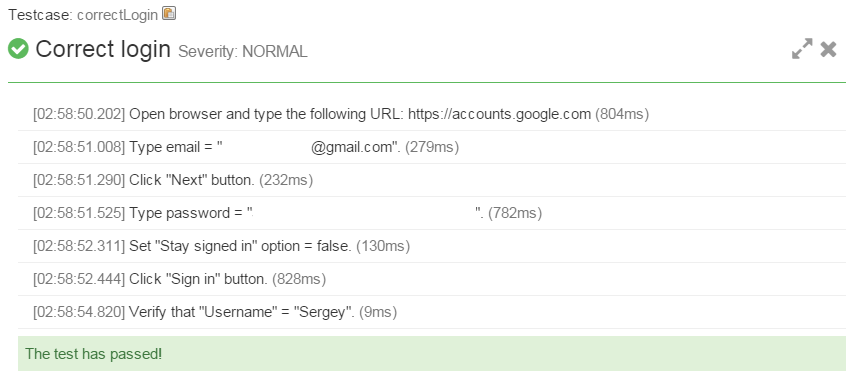
В качестве постскриптума хотелось бы подчеркнуть, что не смотря на скептическое отношение многих к излишнему синтаксическому сахару, так или иначе, он делает наш код более читабельным и понятным.
Цель приведенных в статье примеров - ознакомление с нововведениями Java 8 интерфейсов, а также - альтернативной реализацией некоторых common сценариев при проектировании доменного слоя автотестов.
Во второй части мы рассмотрим более сложный пример использования интерфейсов при проектировании кастомных элементов в качестве альтернативы By локаторам.
Ставим лайки, если данная статья показалась вам интересной и полезной.
П.С. Полная версия исходников будет опубликована на GitHub после выхода второй части. ![]()