По ходу конструирования “велосипедного” тестового фреймворка задался вопросом, как же хранить и использовать SQL запросы, которые например необходимы для проверки создания\изменения записей в БД?
С ходу в голову пришли 3 варианта:
в коде самого теста
в виде .sql или какого либо ресурса
накрутить поверх всего ORM (на сколько кстати хорошая идея? не
overengineering? )
Поделитесь у кого есть какие идеи или даже решения по этому поводу.
Если речь о джаве, то я подключал Hibernate ORM. У нас продакшен база Oracle, а тестовые данные лежат в MySQL. При этом еще куча окружений, где нужно иметь возможность гибкого переключения. Базы можно использовать одновременно без ограничений на чтение / запись / кол-во потоков и т.п. Для NoSQL фанатов тоже есть свои ORM. Недавно постил статью в БЗ по работе с БД via ORM. Можете попробовать данный подход и оценить его эффективность по сравнению с чистым jdbc.
Использую python, а БД Oracle. Но по сути это не важно. Мне просто интересно кто и как реашет такие задачи. Может чего нового для себя открою, или поменяю свое мнение Спасибо за ответ, погляжу твой пост.
Ну я бы сказал так, все зависит от потребностей (сложности sql, переиспользования sql, уровня доступа и т.д.). Но как для автоматизации можно вообще использовать объектный подход обращения к БД. Благо фреймворков и ORM различных хватает, например http://ponyorm.com/
Например вот такой вот sql
SELECT "c"."id"
FROM "Customer" "c"
LEFT JOIN "Order" "order-1"
ON "c"."id" = "order-1"."customer"
GROUP BY "c"."id"
HAVING coalesce(SUM("order-1"."total_price"), 0)
можно записать в виде генератора и получить объекты на выходе
select(c for c in Customer if sum(c.orders.price) > 1000)
А по поводу хранения. Хранить лучше так как тебе будет удобнее поддерживать код. У меня например в коде все находиться возле тестов, при разборе полетов я имею быстрый доступ к механизму выборки если нужно.
А каким образом вы эти данные используете в тестах? Создаете отдельный класс с геттерами и сетерами и уже потом вытягивая данные из БД применяете их к переменным? Или как то оперируете с массивами? Просто о самом подходе хотел бы получше узнать. Спасибо
В самом базовом случае создается копия таблицы БД в виде Java класса. При этом филды, как и сам класс, аннотируются спец. JPA аннотациями для того, чтобы осуществить связь. Посредством геттеров осуществляется чтение данных. При помощи сеттеров - запись. Приведенный по ссылке механизм использует DataProvider в связке с Generic DAO, чтобы заполнять Java сущности данными из таблиц с возможностью сохранения в случае внесения каких-либо изменений. Т.е. в тестах вы будете оперировать непосредственно объектами-отражениями таблиц. Итого, никаких явных SQL команд + полу-автоматически генерируемые Java сущности = максимально простой способ работы с данными при минимальной начальной конфигурации.
Я просто наладил прикрутил базу данных, но вот данные я беру в виде массива, вы в предыдущих темах говорили, это не правильно. Хоть я приблизительно понял, но не могли бы вы простенький пример описать тут, то что выше описали. Буду очень благодарен.
Зависит от потребностей. Если у тебя таких запросов 1-2, то можно и в коде тестов хардкодить, либо вынести во внешний источник (файл, sqlite).
ORM нужны, если у тебя идет динамическая работа с БД: различные выборки, возможность писать гибкие запросы, поддержка нескольких параллельных сессий с БД и т.д.
Если тебе надо лазить в БД тестируемого приложения, то однозначно ORM не нужен. Если ты хочешь в своей БД хранить тестовые данные, которые тебе надо выбирать по определенным критериям, задаваемым тестами, то тут ORM будет в тему.
Но начать можно с простого JDBC. Если архитектура фреймворка правильная и тесты абстрагированы от того способа, которым они получают данные на вход, то с переходом на ORM проблем не будет.
Смотрел сегодня Pony ORM, на первый взгляд вроде ничего. А для него есть какой нибудь генератор моделей по готовой БД, желательно Oracle? (подобная фишка есть Peewee, но без Oracle ) В проекте иногда “штормит” БД и без генератора будет туговато )
Я пока не решил если честно, что для меня полезнее было бы. Никаких праллельных сессий не будет пока что, с гибкими запросами тоже не уверен, что будет. Весь сайт это куча форм, для которых откуда-то нужно брать тестовые данные. Но опять же я не уверен, что я сделал все правильно. У меня есть в БД 3 таблички (form,element,element_in_form). В своем framework использовал hibernate. Вытягиваю я данные для конкретной формы:
public class ElementDAOImpl implements ElementDAO {
public List<Element> getAllField(String nameClass) throws SQLException {
Session session = null;
List<Element> elements = new ArrayList<Element>();
try{
session = HibernateUtil.getSessionFactory().openSession();
elements = session.createCriteria(Element.class).createAlias("form", "form").add(Restrictions.like("form.name", nameClass)).list();
}catch(Exception e){
JOptionPane.showMessageDialog(null, e.getMessage(), "Error I/O", JOptionPane.OK_OPTION);
}finally{
if(session !=null && session.isOpen()){
session.close();
}
}
return elements;
}
Но опять же у меня сомнения, а действительно ли для всех моих форм я должен был создавать только 3 таблицы?
Сомнения - это нормально
Я так понял у тебя связываются множество элементов и множество таблиц? Для связи многие-ко-многим трех таблиц должно быть достаточно
Но если это единственный кейс, то ORM тут не нужен, да и SQL-запрос практически один, в который подставляется только имя формы. Можно было просто в Sqlite это всё держать и доставать через JDBC. Ну а если так работает, то и хорошо, да и знания Hibernate лишними не будут
Работает то оно, работает =) Но что если я скажу, что когда в админке на какой либо форме добавляется новое значение, я лезу в базу данных и добавляю это поле вручную и указываю связь с таблицей? Это правильно?
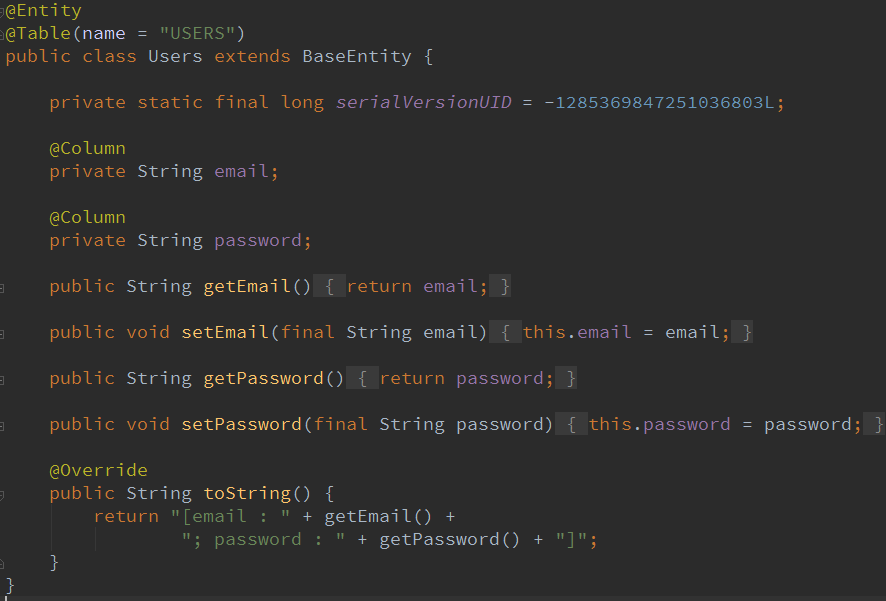
Все предельно просто и понятно. Говорим хибернейту, что данный класс - сущность, ссылающаяся на таблицу USERS, которая в свою очередь содержит колонки email / password.
Но вам ведь для одного теста не нужны все записи таблицы, правильно? Вам нужен только 1 юзер. Я не беру сейчас во внимание сценарии, когда вам нужно будет прогнать один и тот же тест с разными данными. Там будет немного другая стратегия. Но в базовом случае, делать полную выборку из таблицы - не оптимально.
А зачем хранить данные для конкретной формы? Слишком велик риск разброса данных, относящихся к совершенно разным сущностям, что может повлечь за собой постоянные изменения многих участков кода / БД. Лично для себя нашел эффективным вариант создания бизнес сущностей + так называемых датасетов для конкретного теста. При этом, датасеты оперируют все теми же бизнес сущностями. К примеру, чтобы осуществить платеж, мне нужно залогиниться в систему, выбрать профайл, загрузить / подписать / отправить платежный документ, верифицировать факт завершения транзакции / сопоставить input / output платежные реквизиты / суммы. Т.е. бизнес сущностями (имеющими реальный value) тут будут выступать: юзер, профайл, файл, платежная карта. Датасет же будет комбинировать в себе все эти сущности (ссылаясь при этом только на конкретные записи, нужные тесту). На этом этапе могут отличаться особенности реализации: т.е. вы все можете организовать на уровне самой БД, либо же производить все манипуляции в коде. It’s up to you. Но потенциальные изменения будут требовать минимум времени и вмешательств в структуру базы.
А как ещё? Можно конечно написать отдельную тулзу, которая лазит по интерфейсу и выискивает все изменения,и на их основании меняет данные в базе. Но что это даст? Тесты на это новое поле от этого не напишутся Хотя, можно конечно и дальше пойти и автоматически генерить стандартные тесты на поле и т.д. Но это уже следующий уровень имхо
В предыдущей теме я описывал свой framework и там была строка в тесте:
@Test
public void testKaraoke(){
***
List<Element> randomValuesKaraoke = app.getDataHelper().getRandomValues(Form.KARAOKE); // устанавливает в базу данных рандомные значения и возвращает список этих значений
***
}
Где Element:
@Entity
@DynamicUpdate(value=true)
@SelectBeforeUpdate(value=true)
@DynamicInsert(value=true)
@Table(name="element")
public class Element {
private Integer id;
private String name;
private String type;
private String nameVariable;
private String value;
private Set<Form> form = new HashSet<Form>();
//
public Element(){
}
@Id
@GeneratedValue(generator="increment")
@GenericGenerator(name="increment", strategy = "increment")
@Column(name="id")
public Integer getID(){
return id;
}
@Column(name="name")
public String getName(){
return name;
}
@Column(name="type")
public String getType(){
return type;
}
@Column(name="nameVariable")
public String getNameVariable(){
return nameVariable;
}
@Column(name="value")
public String getValue(){
return value;
}
public void setID(Integer id){
this.id = id;
}
public void setName(String name){
this.name = name;
}
public void setType(String type){
this.type = type;
}
public void setNameVariable(String nameVariable){
this.nameVariable = nameVariable;
}
public void setValue(String value){
this.value = value;
}
@ManyToMany(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinTable(name="element_in_form", joinColumns = {@JoinColumn(name = "element_ID")}, inverseJoinColumns = {@JoinColumn(name="form_ID")})
public Set<Form> getForm() {
return this.form;
}
public void setForm(Set<Form> form) {
this.form = form;
}
}
В принципе я понимаю, что строка слишком сложная для человека который будет писать тесты. Каким образом я ее должен преобразовать? Как она должна выглядеть в идеале? Если не хватает какого-то кода, скажите.
Неужели так сложно прочитать статью в блоге целиком и сравнить ваш код с приведенными примерами? К тому же, вам уже отвечали в другой теме, что данная строка никак не связана с доменной логикой. Вы на бумаге точно так же описываете данные для теста?
 testomat.io управление авто тестами
testomat.io управление авто тестами
 ) В проекте иногда “штормит” БД и без генератора будет туговато )
) В проекте иногда “штормит” БД и без генератора будет туговато )