 testomat.io управление авто тестами
testomat.io управление авто тестамиВсем привет,
Как и обещал, выкладываю статью по архитектуре и концепции POM (http://pom.readthedocs.io/, GitHub - schipiga/pom: Documentation http://pom.readthedocs.io/).
Почему нужен враппер над selenium
POM - это микрофреймворк, имплементирующий page object model для тестирования webUI-приложений через selenium. POM берет на себя обязанности по низкоуровневым манипуляциям с DOM-элементами через selenium.
Часто случается видеть в коде (особенно начинающих специалистов в автоматизации) методов page зашитые константы селекторов, слипы и прочие признаки плохо “пахнущего” кода. С одной стороны - вроде бы все по феншую: page-object-pattern, скрытая логика реализации. Но на деле имеем повторяющийся плохочитаемый плохоструктурированный код.
Важно соблюдать правило: “логика реализации должна быть отделена от логики использования”. Очень хочется работать со структурой page в объектном стиле, о чем и говорит page object pattern. Очень хочется обращаться к UI-элементам как к объектам, вызывать у них методы и следовать иерархии вложения элементов. Вот это и делает POM.
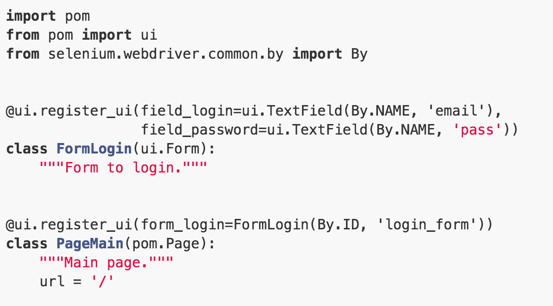
Использование POM позволяет декларативно описать структуру и иерархию страницы один раз (при условии что верстка, а соответственно селекторы и структура, не меняются) (н-р: mos-horizon/containers.py at v9.1 · Mirantis/mos-horizon · GitHub), и затем уже у себя в тестах или стэпах обращаться к UI-элементам так, как того требует тест или стэп (mos-horizon/containers.py at v9.1 · Mirantis/mos-horizon · GitHub).
Какие типы элементов выделяет POM
POM делит все UI-элементы на две большие категории:
- простые элементы (кнопки, текстовые поля, и т.п.) (pom/button.py at master · schipiga/pom · GitHub)
- контейнеры (страницы, блоки, таблицы, списки), которые могут содержат внутри себя простые элементы. При этом у контейнеров также есть все методы типа click() и т.п., которые доступны простым элементам. (pom/table.py at master · schipiga/pom · GitHub)
Page также является контейнером, что в общем-то вполне очевидно. Технически, контейнер является mixin-классом (pom/base.py at master · schipiga/pom · GitHub), который подмешивается к базовому UI-классу (pom/base.py at master · schipiga/pom · GitHub).
Как компонуется иерархия UI-элементов
Контейнеры регистрируют (pom/base.py at master · schipiga/pom · GitHub) внутри себя другие UI-элементы (простые и контейнеры), создавая иерархию. При этом механизм регистрации работает следующим образом:
- При непосредственно регистрации ui, создается шаблон UI-элемента с селектором.
- К классу добавляется property, связанный с созданным шаблоном
- При вызове property у инстанциированного контейнера создается клон из шаблона, которому указывается родительский элемент (контейнер)
- Клон кэшируется и при последующих вызовах уже берется из кэша, а не клонируется заново.
Таким образом все инстансы одного контейнера будут иметь разные клоны с одного зарегистрированного UI-шаблона. Это важно н-р при многопоточном запуске тестов, т.к. позволяет писать by design потокобезопасные тесты.
Как реализуется ожидание UI-элементов
Большинство методов UI-элементов (pom/base.py at master · schipiga/pom · GitHub) имеют декоратор @wait_for_presence. Возникает вопрос - зачем, если уже selenium внутри себя реализует implicit_wait, который умеет дожидаться элемент в DOM’e. На это есть несколько архитектурных обоснований:
- seleinum - это библиотека низкоуровневой работы с DOM и в ней implicit_wait используется, чтобы дождаться появления элемента именно в DOM’e, даже если он будет при этом невидим (а следовательно некликабелен). Так что если элемент есть в DOM’e, но еще не стал видимый, то implicit_wait вас не спасет и нужно изобретать хаки. POM по-другому смотреть на присутствие UI-элемента: с точки зрения пользователя, UI-элемент присутствует, если он видим. И кастомный waiter позволяет легко этого добиться (пусть и ценой постоянных запросов к driver’у).
- implicit_wait потому так называется, что он неявный, и происходит неявно, даже тогда, когда вам этого не нужно, тратя на это драгоценное время теста. Н-р: если нужно сразу сказать: присутствует элемент или нет, implicit_wait этого вам не позволит, попытавшись сперва дождаться элемента. Обычно для обхода этого используется хак (н-р в виде контекст-менеджера): сперва implicit_wait устанавливается на 0, затем запрашивается статус присуствия элемента, потом восстанавливается прежнее значение implicit_wait. Но implicit_wait - это метод driver’a, а элемент POM’a знает только про selenium-элемент с которым связан и ничего не знает про driver (responsibility segregation). Протаскивать вглубь POM-элементов знания о driver - это был бы хак.
- POM использует механизм кэширования selenium-элемента, чтобы не обращаться без необходимости к driver’у. При этом если кэш тухнет, нужно быстро перезапросить selenium-элемент, изменив значение implicit_wait на 0, что возвращает к предыдущему пункту.
- отказ от implicit_wait позволило единообразно организовать у UI-элемента методы wait_for_presence, wait_for_absence, т.к. в тестах довольно часто бывает нужно убедиться, что после действий элемент появился или исчез во времени.
Как работает механизм кэширования UI-элементов
POM выстраивает иерархию UI-элементов, при этом каждый UI-элемент связан с selenium-элементом, через которое производится действие в браузере. Selenium обеспечивает методы поиска внутри элемента find_element и find_elements, что позволяет проводить иерархичный поиск - это же и является сердцем POM’a. Когда в цепочке производится действие н-р: page.block_1.block_2.block_3.button.click(), при вызове метода click, элемент button ищет внутри родителя cвязанный selenium-элемент, поскольку родитель block_3 пуст - он начинает искать свой связанный selenium-элемент внутри своего родителя block_2 и так далее. При первичном запросе на каждом уровне иерархии производится выборка selenium-элемента с последующим его кэшированием. При последующем вызове метода у UI-элемент, он достается сперва из кэша, и если он устарел (PRESENCE_ERRORS = (exceptions.StaleElementReferenceException, exceptions.NoSuchElementException)), то производится перевыборка с обращением к родителям.
Стоит отметить что POM не использует find_elements, хотя имеет поддержку. Это связано с тем, что POM работает с каждым объектом индивидуально, храня его в кэше. На больших списках или таблицах данных это может приводить к длительному времени выполнения (хотя думаю даже на голом selenium с find_elements время опроса свойств каждого элемента станет существенным, тут уж проще использовать вызов js и выполнять калькуляцию на стороне браузера), однако selenium - это впервую очередь инструмент функционального тестирования (функциональность можно проверить и на списке с 10 элементами), и никак не инструмент нагрузочного тестирования.
На этом все, наверняка что-то упустил, поэтому готов ответить на вопросы.
import unittest
import pom
from pom import ui
from selenium.webdriver.common.by import By
@ui.register_ui(field_login=ui.TextField(By.NAME, 'email'),
field_password=ui.TextField(By.NAME, 'pass'))
class FormLogin(ui.Form):
"""Form to login."""
@ui.register_ui(form_login=FormLogin(By.ID, 'login_form'))
class PageMain(pom.Page):
"""Main page."""
url = '/'
@ui.register_ui(
alert_message=ui.Block(By.CSS_SELECTOR, 'div.uiContextualLayerPositioner'))
class PageLogin(pom.Page):
"""Login page."""
url = '/login'
@pom.register_pages([PageMain, PageLogin])
class Facebook(pom.App):
"""Facebook web application."""
def __init__(self):
super(Facebook, self).__init__('https://www.facebook.com', 'firefox')
self.webdriver.maximize_window()
self.webdriver.set_page_load_timeout(30)
class TestCase(unittest.TestCase):
def setUp(self):
self.fb = Facebook()
self.addCleanup(self.fb.quit)
def test_facebook_invalid_login(self):
"""User with invalid credentials can't login to facebook."""
self.fb.page_main.open()
with self.fb.page_main.form_login as form:
form.field_login.value = 'admin'
form.field_password.value = 'admin'
form.submit()
assert self.fb.current_page == self.fb.page_login
assert self.fb.page_login.alert_message.is_present
 Придётся публиковать
Придётся публиковать